cURL is an application that can be used to retrieve any Internet file that uses the standard URL format — http://, ftp://, gopher://, etc. Its power and flexibility can be added to applications by using the libcurl library, whose API can be accessed easily using most of the commonly used scripting and programming languages.
cURL is an application that can be used to retrieve any Internet file that uses the standard URL format — http://, ftp://, gopher://, etc. Its power and flexibility can be added to applications by using the libcurl library, whose API can be accessed easily using most of the commonly used scripting and programming languages.
So, how does cURL differ from some of the other command-line URL retrieval tools such as WGET? Both do very similar things, and can be coaxed to retrieve large lists of files or even mirror entire Web sites. In fact, for the automated retrieval of single files for the Internet for storage on local filesystems — such as downloading source files onto servers for building applications — WGET’s syntax is the simplest to use.
However, for simple baseline testing, WGET lacks cURL’s ability to produce timing results that can be written to an output file in a user-configurable format. cURL gathers a large amount of data about a transfer that can then be used for analysis or logging purposes. This makes it a step ahead of WGET for baseline testing.
cURL Installation
For the purposes of our testing, we have used cURL 7.10.5-pre2 as it adds support for downloading and interpreting GZIP-encoded content from Web servers. Because it is a pre-release version, it is currently only available as source for compiling. The compilation was smooth, and straight-forward.
$ ./configure --with-ssl --with-zlib
$ make
$ make test
[...runs about 120 checks to ensure the application and library will work as expected..]
# make install
The application installed in /usr/local/bin on my RedHat 9.0 laptop.
Testing cURL is straight-forward as well.
$ curl http://slashdot.org/
[...many lines of streaming HTML omitted...]
Variations on this standard theme include:
- Send output to a file instead of STDOUT
$ curl -o ~/slashdot.txt http://slashdot.org/
- Request compressed content if the Web server supports it
$ curl --compressed http://slashdot.org/
- Provide total byte count for downloaded HTML
$ curl -w %{size_download} http://slashdot.org/
Baseline Testing with cURL
With the application installed, you can now begin to design a baseline test. This methodology is NOT a replacement for true load testing, but rather a method for giving small and medium-sized businesses a sense of how well their server will perform before it is deployed into production, as well as providing a baseline for future tests. This baseline can then be used as a basis for comparing performance after configuration changes in the server environment, such as caching rule changes or adding solutions that are designed to accelerate Web performance.
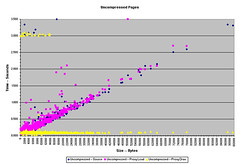
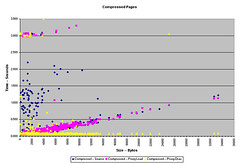
To begin, a list of URLs needs to be drawn up and agreed to as a baseline for the testing. For my purposes, I use the files from the Linux Documentation project, intermingled with a number of images. This provides the test with a variety of file sizes and file types. You could construct your own file-set out of any combination of documents/files/images you wish. However, the file-set should be large — mine runs to 2134 files.
Once the file-set has been determined, it should be archived so that this same group can be used for future performance tests; burning it to a CD is always a safe bet.
Next, extract the filenames to a text file so that the configuration file for the tests can be constructed. I have done this for my tests, and have it set up in a generic format so that when I construct the configuration for the next test, I simply have to change/update the URL to reflect the new target.
The configuration of the rest of the parameters should be added to the configuration file at this point. These are all the same as the command line versions, except for the URL listing format.
- Listing of test_config.txt
-A "Mozilla/4.0 (compatible; cURL 7.10.5-pre2; Linux 2.4.20)"
-L
-w @logformat.txt
-D headers.txt
-H "Pragma: no-cache"
-H "Cache-control: no-cache"
-H "Connection: close"
url="http://www.foobar.com/1.html"
url="http://www.foobar.com/2.png"
[...file listing...]
In the above example, I have set cURL to:
- Use a custom User-Agent string
- Follow any re-direction responses that contain a “Location:” response header
- Dump the server response headers to headers.txt
- Circumvent cached responses by sending the two main “no-cache” request headers
- Close the TCP connection after each object is downloaded, overriding cURL’s default use of persistent connections
- Format the timing and log output using the format that is described in logformat.txt
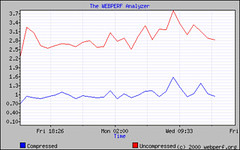
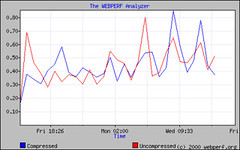
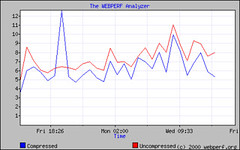
Another command-line option that I use a lot is –compressed, which, as of cURL 7.10.5, handles both the deflate and gzip encoding of Web content, including decompression on the fly. This is great for comparing the performance improvements and bandwidth savings from compression solutions against a baseline test without compression. Network administrators may also be interested in testing the improvement that they get using proxy servers and client-side caches by inserting –proxy <proxy[:port]> into the configuration, removing the “no-cache” headers, and testing a list of popular URLs through their proxy servers.
The logformat.txt file describes the variables that I find of interest and that I want to use for my analysis.
\n
%{url_effective}\t%{http_code}\t%{content_type}\t%{time_total}\t%{time_lookup}\t /
%{time_connect}\t%{time_starttransfer}\t{size_download}\n
\n
These variables are defined as:
- url_effective: URL used to make the final request, especially when following re-directions
- http_code: HTTP code returned by the server when delivering the final HTML page requested
- content_type: MIME type returned in the final HTML request
- time_total: Total time for the transfer to complete
- time_lookup: Time from start of transfer until DNS Lookup complete
- time_connect: Time from start of transfer until TCP connection complete
- time_starttransfer: Time from start of transfer until data begins to be returned from the server
- size_download: Total number of bytes transferred, excluding headers
As time_connect and time_starttransfer are cumulative from the beginning of the transfer, you have to do some math to come up with the actual values.
TCP Connection Time = time_connect – time_lookup
Time First Byte = time_starttransfer – time_connect
Redirection Time = time_total – time_starttransfer
If you are familiar with cURL, you may wonder why I have chosen not to write the output to a file using the -o <file> option. It appears that this option only records the output for the first file requested, even in a large list of files. I prefer to use the following command to start the test and then post-process the results using grep.
$ curl -K test_config.txt >> output_raw_1.txt
[...lines and lines of output...]
$ grep -i -r "^http://www.foobar.com/.*$" output_raw_1.txt >> output_processed_1.txt
And voila! You now have a tab delimited file you can drop into your favorite spreadsheet program to generate the necessary statistics.