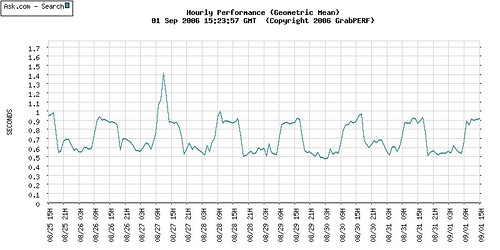
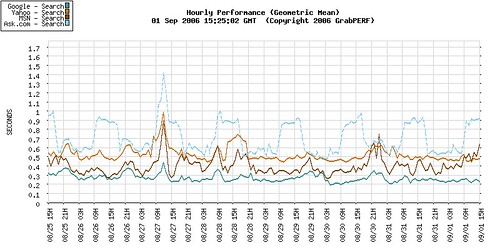
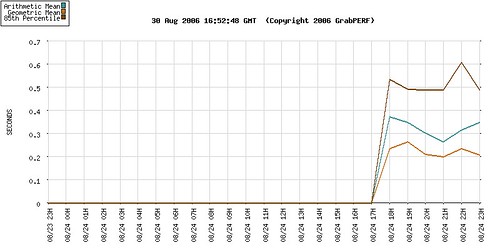
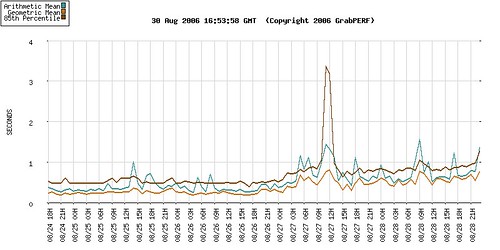
Two years ago I created a series of five blog articles, aimed at both business and technical readers, with the goal of explaining the basic statistical concepts and methods I use when analyzing Web performance data in my role as a Web performance consultant.
Most of these ideas were core to my thinking when I developed GrabPERF in 2005-2006, as I determined that it was vital that people not only receive Web performance measurement data for their site, but they receive it in a way that allows them to inform and shape the business and technical decisions they make on a daily basis.
While I come from a strong technical background, it is critical to be able to present the data that I work with in a manner that can be useful to all components of an organization, from the IT and technology leaders who shape the infrastructure and design of a site, to the marketing and business leaders who set out the goals for the organization and interact with customers, vendors and investors.
Providing data that helps negotiate the almost religious dichotomy that divides most organizations is crucial to providing a comprehensive Web performance solution to any organization.
These articles form the core of an ongoing series of discussion focused on the the pitfalls of Web performance analysis, and how to learn and avoid the errors others have already discovered.
The series went over like a lead balloon and this left me puzzled. While the basic information in the articles was technical and focused on the role that simple statistics play in affecting Web performance technology and business decisions inside an organization, they formed the core of what I saw as an ongoing discussion that organizations need to have to ensure that an organization moves in a single direction, with a single purpose.
I have decided reintroduce this series, dredging it from the forgotten archives of this blog, to remind business and IT teams of the importance of the Web performance data they use every day. It also serves as a guide to interpreting the numbers that arise from all the measurement methodologies that companies use, a map to extract the most critical information in the raging sea of data.
The five articles are:
- Web Performance, Part I: Fundamentals
- Web Performance, Part II: What are you calling average?
- Web Performance, Part III: Moving Beyond Average
- Web Performance, Part IV: Finding The Frequency
- Web Performance, Part V: Baseline Your Data
I look forward to your comments and questions on these topics.