Ah, Cloudflare. You claim to be security focused and help customers block threats to their sites, including unwanted bots. So, when are you going to clean your own house?
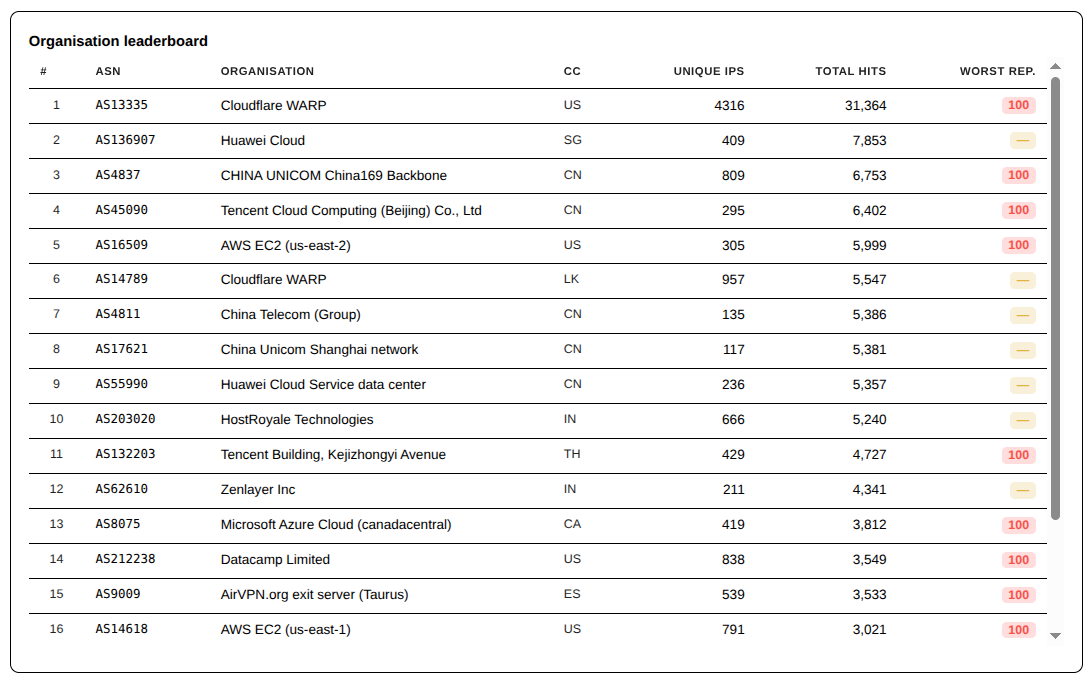
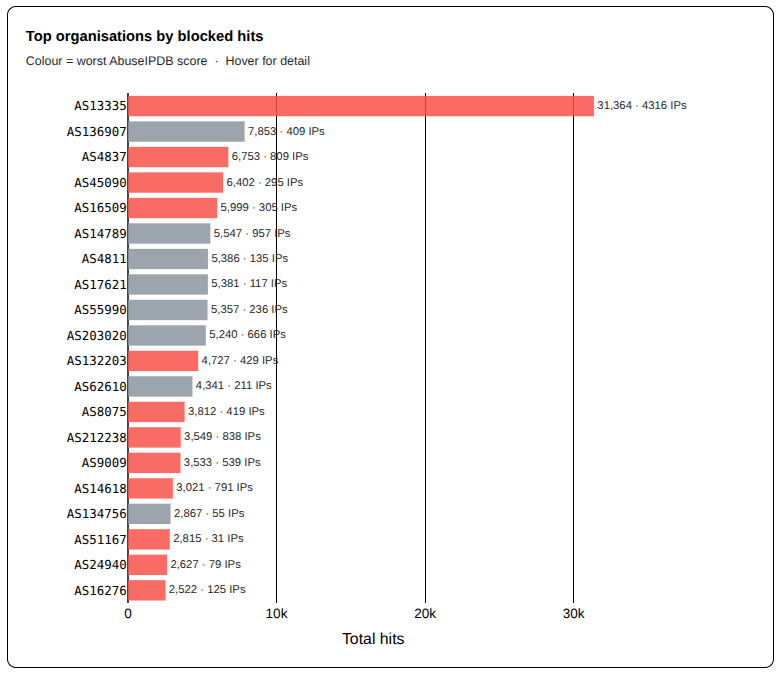
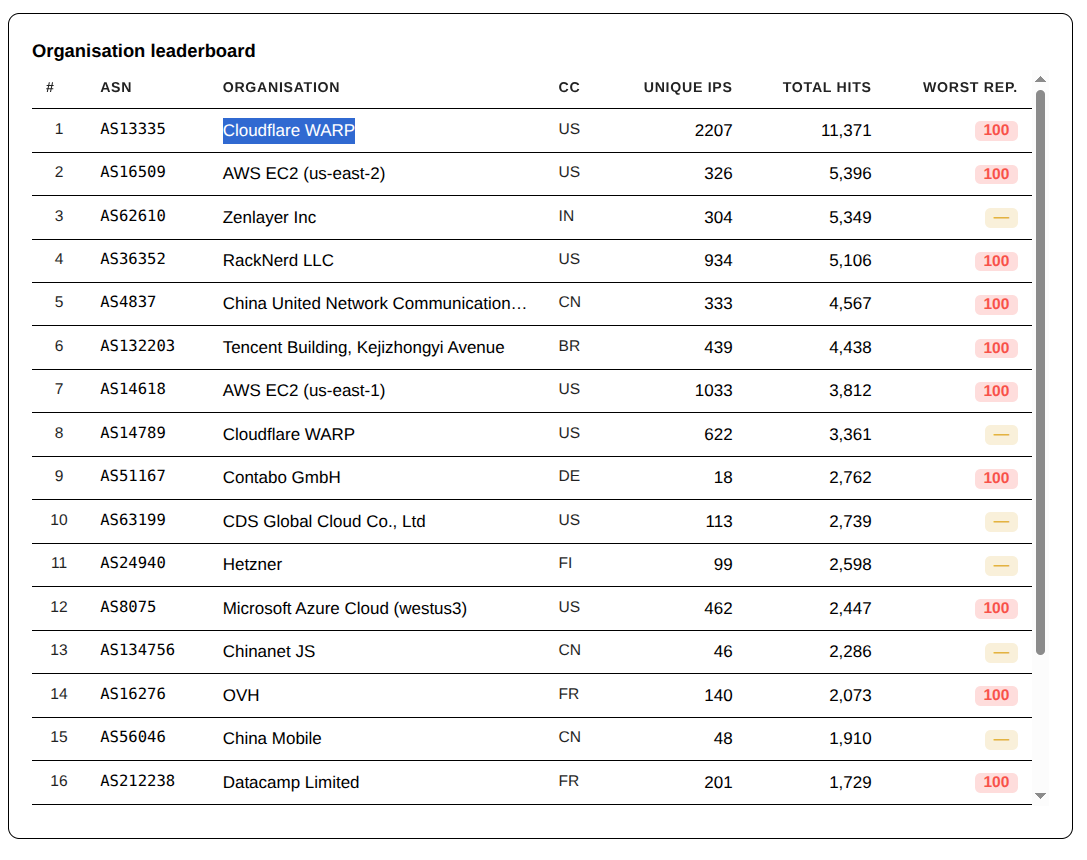
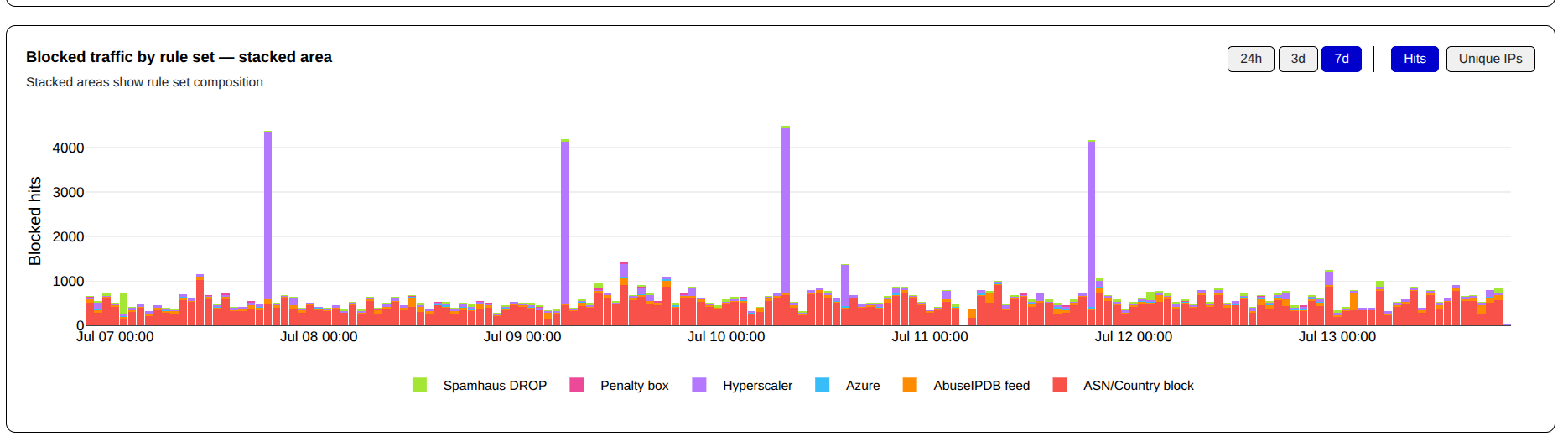
This week, like last week, the single largest source of traffic captured by my firewall was, again, AS13335 – Cloudflare WARP. The firewall blocked nearly 4x the amount of hits when compared to the next closest ASN; and that was from just one of their ASNs.
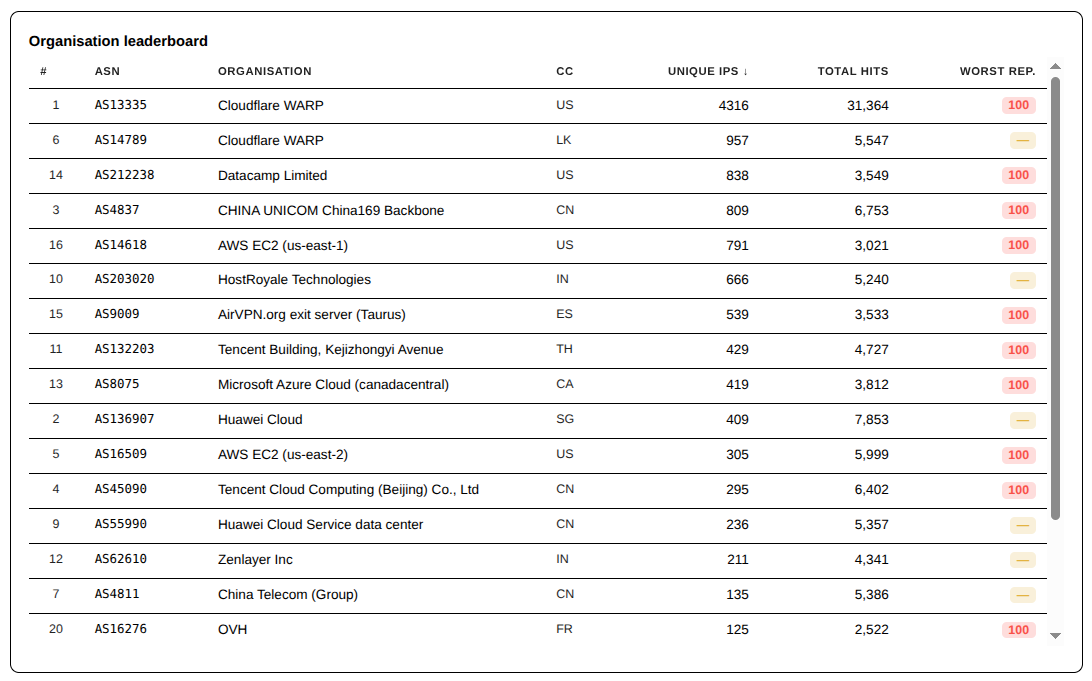
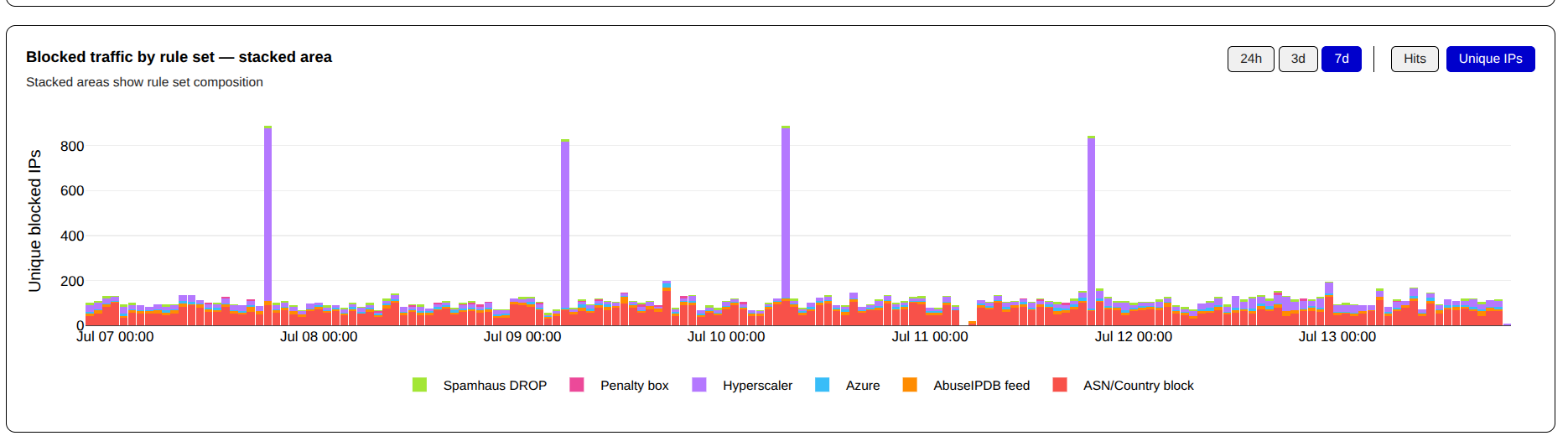
When the data is sorted by the number of unique IPs hitting the server, Cloudflare comes first and second, with AS14789 contributing a smaller number of hits.
Top ASNs – By Hits – Last 7 DaysTop ASNs – By Unique IPs – Last 7 Days
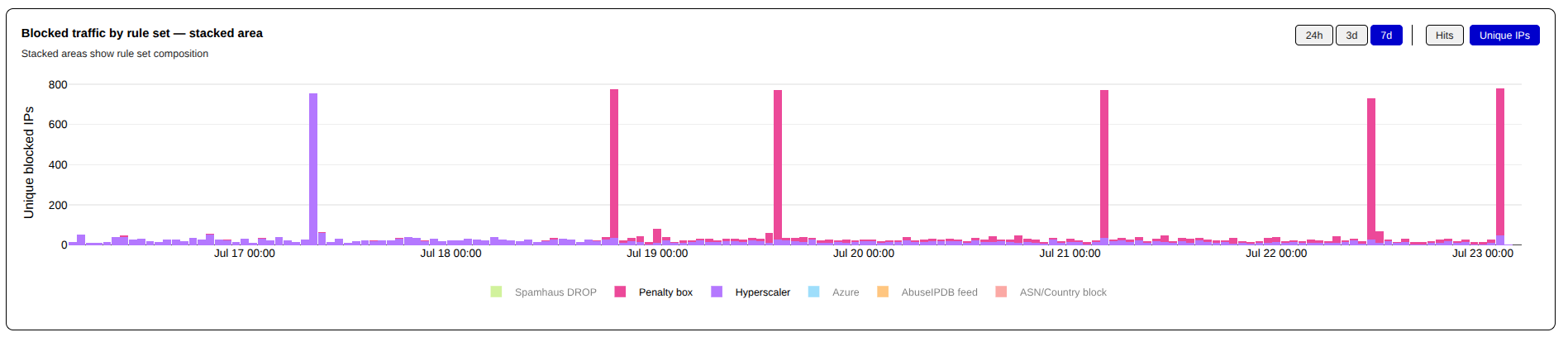
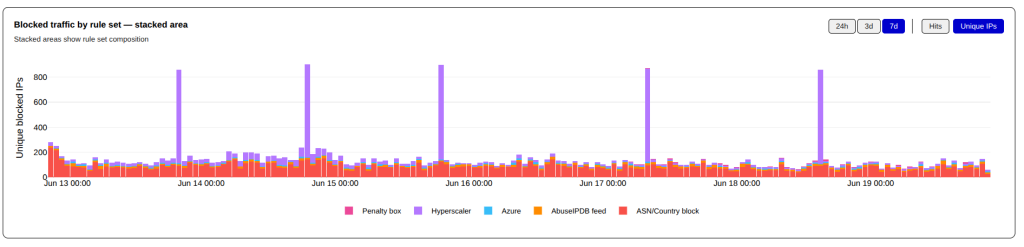
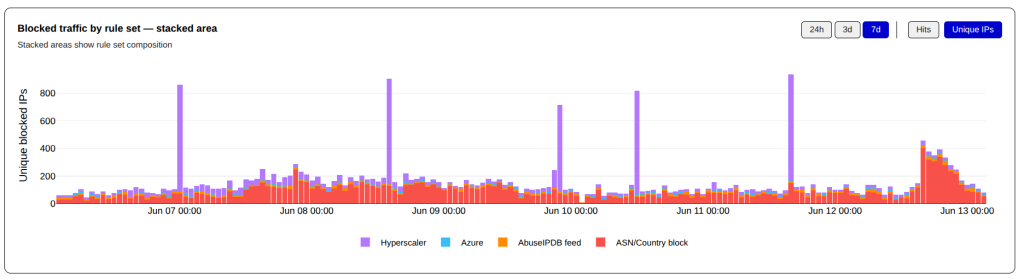
You can see the scope of the unwanted traffic from Cloudflare WARP even more clearly when it is charted.
Top ASNs – By Hits – Last 7 Days
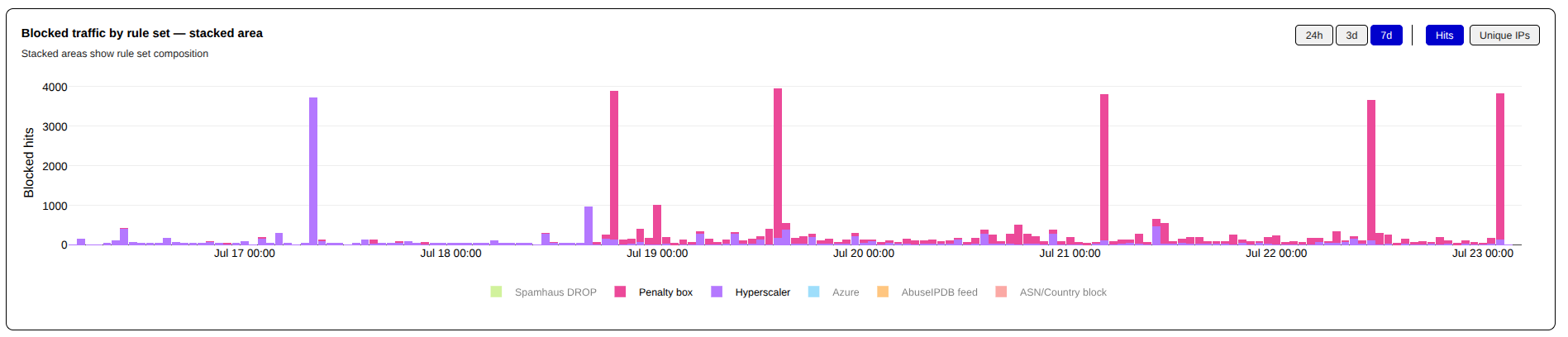
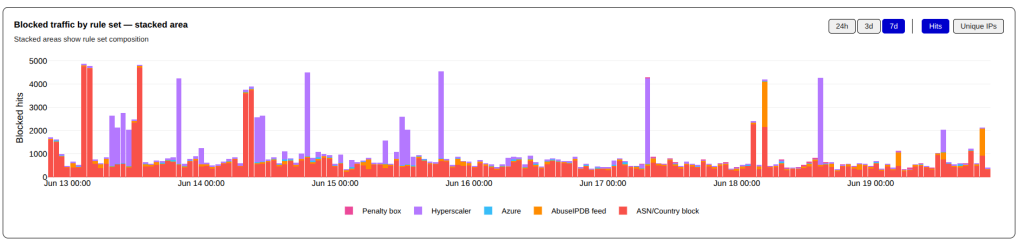
Since the last update, I have had to add a large number of Cloudflare CIDR blocks to my penalty_box list that is before the shield_hyperscaler rules in my firewall rules. The Penalty Box is a complete drop rule, with a time limit. Unfortunately, pretty much all the CIDR blocks in the penalty_box qualify for permanent blocks, and I will likely move them their in the near future.
You can see when I migrated the Cloudflare CIDR Blocks to the penalty_box ruleset in these time charts — the red items are shield_hyperscaler while the purple is penalty_box (I apologize to my brethren who have red/green color blindness).
Hits by Ruleset – Last 7 DaysUnique IPs by Ruleset – Last 7 Days
I will continue to watch this over the next few weeks; if Cloudflare WARP continues to be this aggressive, they will end up in the permanent block ruleset.
Google CrUX is a great publicly available source of performance data that is not only good for analyzing the performance of a single site over time, but also a good way to create a comparative performance benchmark using shared metrics with agreed upon definitions.
The CrUX History API allows for data to be extracted, analyzed, and compared using these metrics. However, it is challenging to use some of the publicly available CrUX Report generators to create a benchmark.
Starting from some reporting I had already developed to use the CrUX History API for my day-job, I extended this to allow for the reporting capability to be extended to anyone who has a CrUX API key (get your own by following the directions here) and a list of URLs they want to compare.
Right now it only accepts domains. I may in the future add the ability to do individual URLs, but this is the easiste to implement.
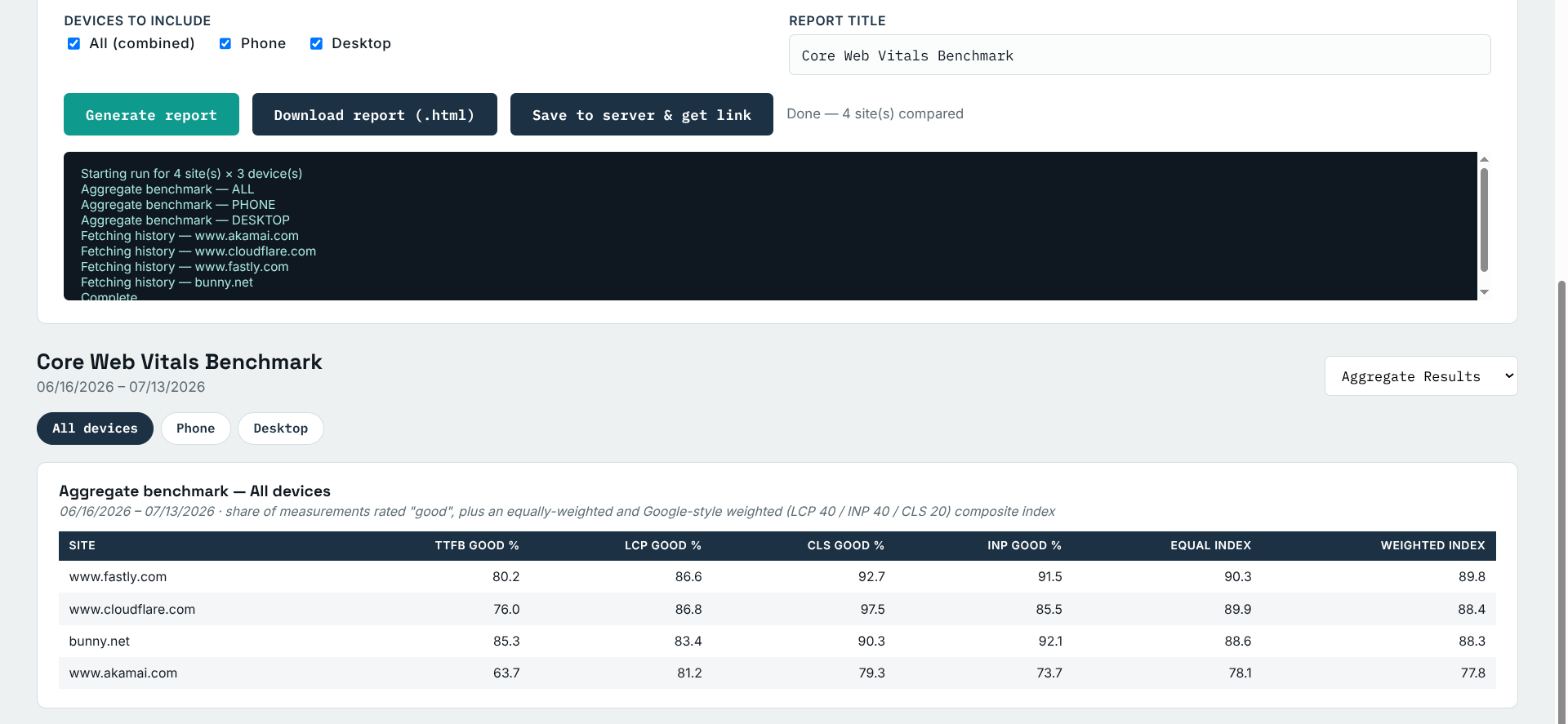
Once you run the report, you get the following output.
Initial Report Output
The report that is generated is viewable right in the page, can be saved to your local drive, or stored on the server for 30 Days. Using the stored on server method, I have created a sample report you can review here.
I hope you get some fun and entertainment from it!
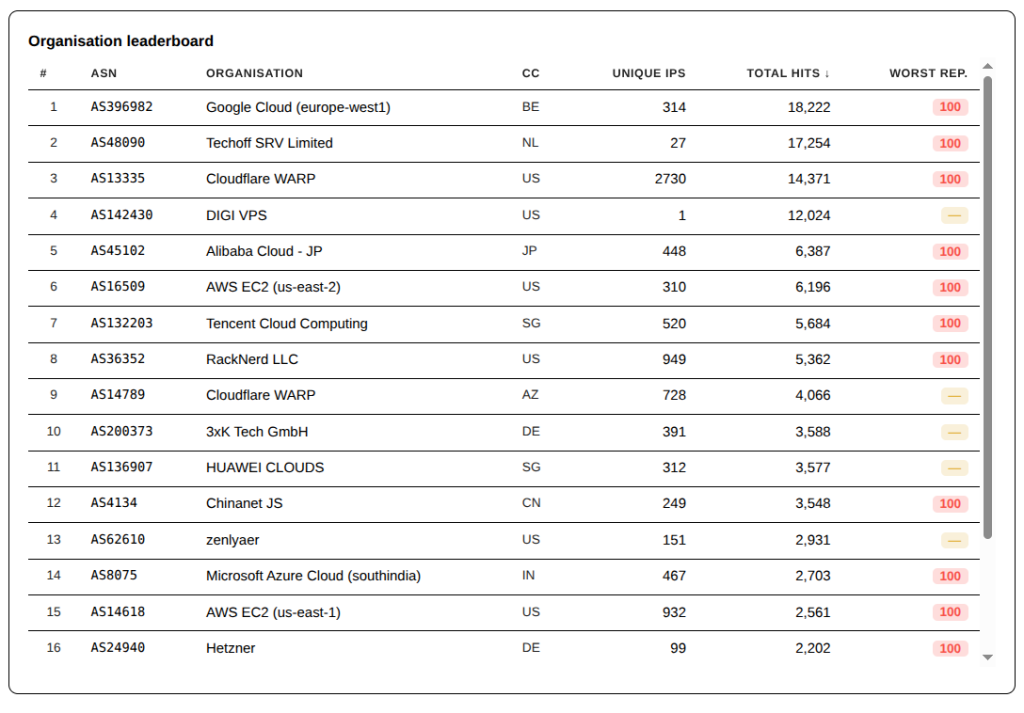
In this week’s edition of the Top Offenders list, there is a new leader in the abuse list: AS13335 – Cloudflare WARP. They have been hitting the site in large bursts for a couple of weeks now, using the anonymity afforded by hiding behind the open VPN Cloudflare provides.
Top ASNs – 7 Days
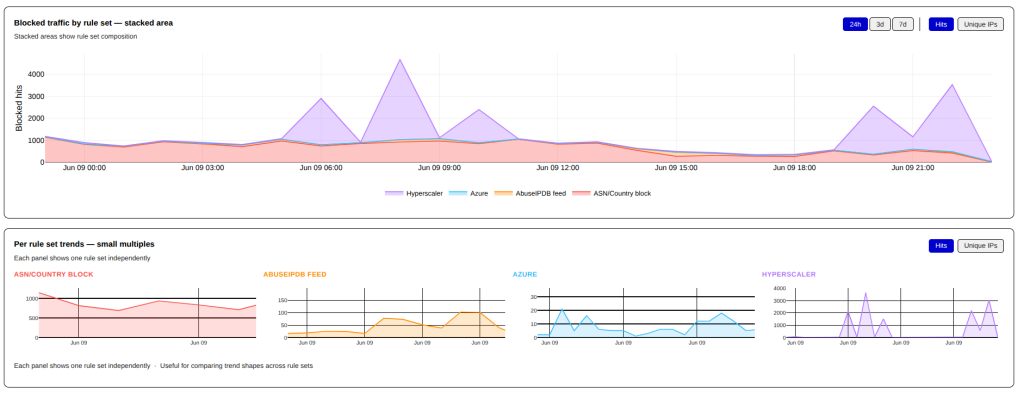
All of the largest surges seen over the last 7 days originate from this single ASN.
Firewall Hits by Hour – Last 7 DaysDistinct IPs by Hour – Last 7 Days
Clouflare is in the shield_hyperscaler ruleset that was discussed in the previous Top Offenders post. This traffic is forced into a rate-limiting situation where a flood of traffic automatically triggers a DROP once a set volume is reached. However, even this is challenging as the Cloudflare surges have the largest amount of IP diversity of all those tracked at the firewall.
In order to be more flexible, the shield_hyperscaler ruleset is applied on a /24 network basis. So even if the attacker tries to hide behind a set of IPs, if they come from a small number of /24 networks, they will end up in the DROP bucket.
On July 10 2026, I retired the 2008 13″ Macbook Aluminum that has been running as my web server/firewall/testbed for the last 4-5 years. A couple of unexpected power events and complete server lockups indicated that this old friend needed a rest.
I replaced it with this — no endorsement on my part; just stating the facts. While a small homelab/office workstation cube may not be to everyone’s liking, I can tell you that with resource-constrained applications where the old Macbook had struggled, the new machine is more than capable.
I had considered buying an old laptop to serve the purpose, but this little box is quiet, unobtrusive, and does what I ask it too.
I’m a little sad to see a laptop that I have been using since 2008 fall out of service, but there comes a point where it just doesn’t do any job anymore.
I’m not getting rid of it. I’m sure I will find a use for it some day. Just like everytime I thought that it was permanently retired. There is always a use for computer hardware of all kinds.
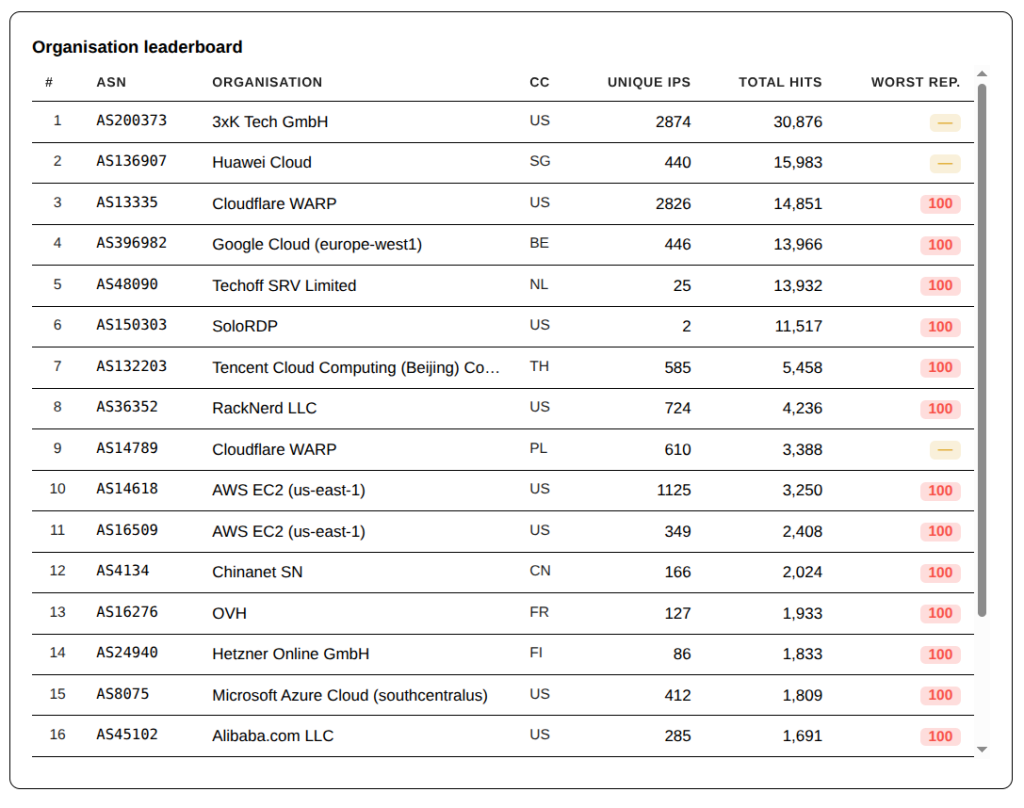
Here is your weekly list of top offenders for your own security reading pleasure.
Big change this week with Google EU West taking the top spot and Techoff SRV Limited, everyone’s favority Andorra-based Bulletproof Hosting Provider (despite company registration listing it as being from the UK and/or the Netherlands depending on how it is examined) taking the number 2 spot. Techoff is also the source of a number of the largest surges against the firewall this week.
Top ASNs – 7 Days
Cloudflare Warp is still a major source of attacks, providing the single source of attackers hiding behind the VPN/Proxy services in this ASN.
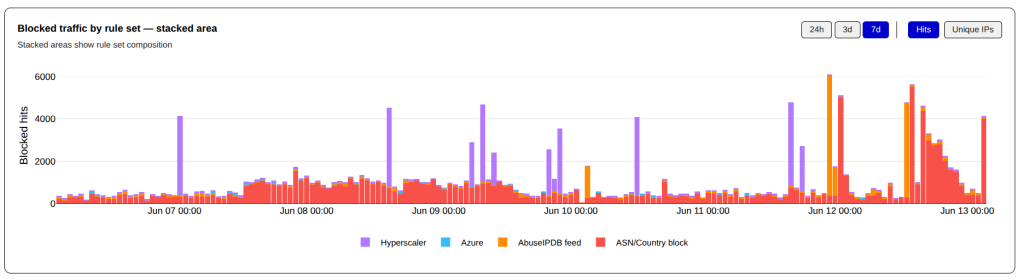
This week was much quieter for Surge events, with most surge events originating from ASNs and CIDR blocks that already exist in the Hyperscaler or Block ASN/CIDR rule lists. Multi-IP surges completely originated from the Hyperscalers while the Block ASN/CIDR surges coming from only a small number of IPs.
Hour by Hits – 7 DaysHours by IPs – 7 Days
A note on the difference between the firewall rulesets. The Block ASN/CIDR rulesets do exactly as advertised — completely block the traffic that reaches them. The Hyperscaler ruleset is rate-limiting and only starts to DROP traffic if the number of connections or number of requests becomes aggressive.
There is also a separate set of ratelimiting for Azure, as Microsoft doesn’t seem to have as much control on bad actors as the other Hyperscalers do.
The current rulesets are:
shield_allow → ACCEPT shield_abuseipdb → DROP shield_penalty → DROP shield_azure → AZURE-RATELIMIT (3/min per IP) shield_hyperscaler → CLOUD-RATELIMIT (10/min per /24) shield_block → DROP
As with everything, the ordering is important. For example, if there is a really aggressive AS8075 (Microsoft) IP that has been flagged by AbuseIPDB to the extent that it appears in the top 10K list that they provide, it gets immediately blocked. If I have found an aggressive IP that appears in none of the lists, I can add it (or the approporate CIDR block) to the Penalty Box ruleset for a set period of time to discourage that traffic.
Another week of interesting learning around what is and isn’t traffic worth completely blocking. Learning that not all traffic can be blocked is one of the the twelve steps of learning to exist within the modern internet.
As a final note, the Spamhaus list of offensive IPV4 addresses (available here) was added as yet another data source that is automatically added into the firewall rules on a daily basis. I will try and provide a sense of how effective this ruleset is next week.
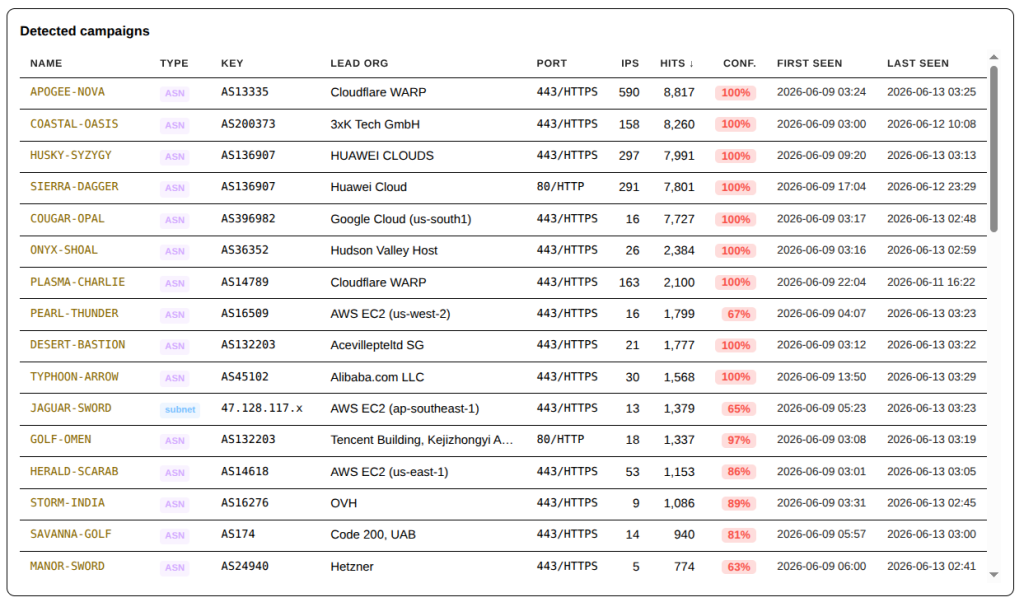
With the visualization system built to capture the data from the Enterprise Shield firewall system, I get to see exactly who the top Offenders are. This is the start of a series that allows me to share with the larger community who exactly has been trying to bring my tiny home web server to its knees.
Top ASNs – 7 Days
Using the Campaign naming schema, you can see many of the same providers showing up and being classified based on timing and attack pattern.
Top Capmpaigns – 7 Days
This has been a busy 7 days for surges in traffic.
Hour by Hits – 7 DaysHours by Unique IPs – 7 Days
The various surges are made up traffic from small numbers of IPs (SoloRDP – AS150303 with 2 IPs for 11,517 firewall hits) to large distributed attacks with huge blocks of IPs (Cloudflare WARP – AS13335 & AS14789; 3xK Tech GmbH– AS200373; etc.).
Overall, it’s been a good learning experience to be able to see a full 7 days of traffic that was previously invisible to me.
When the Enterprise Shield firewall system was re-written, one of the things I worked on with Claude was the creation of an HTML dashboard that could share details on what and who was hitting the system.
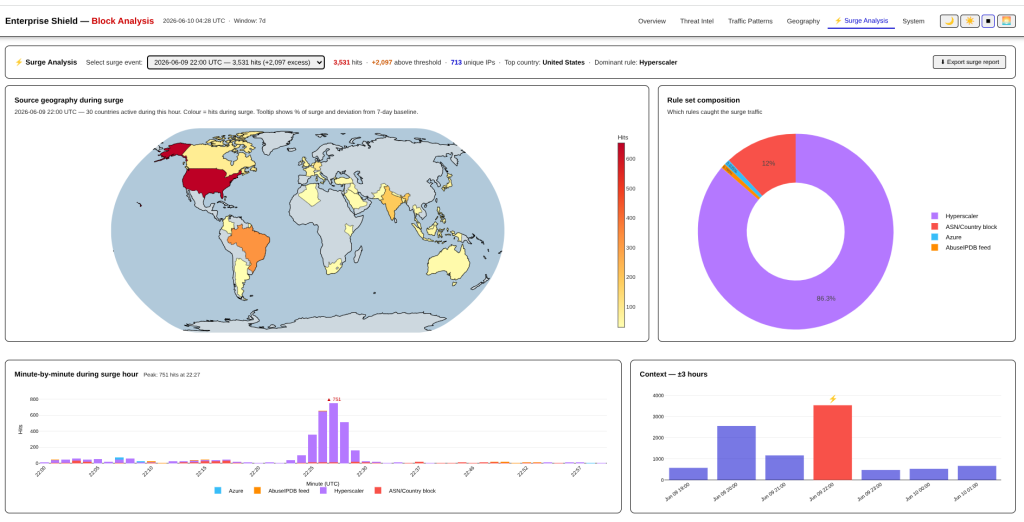
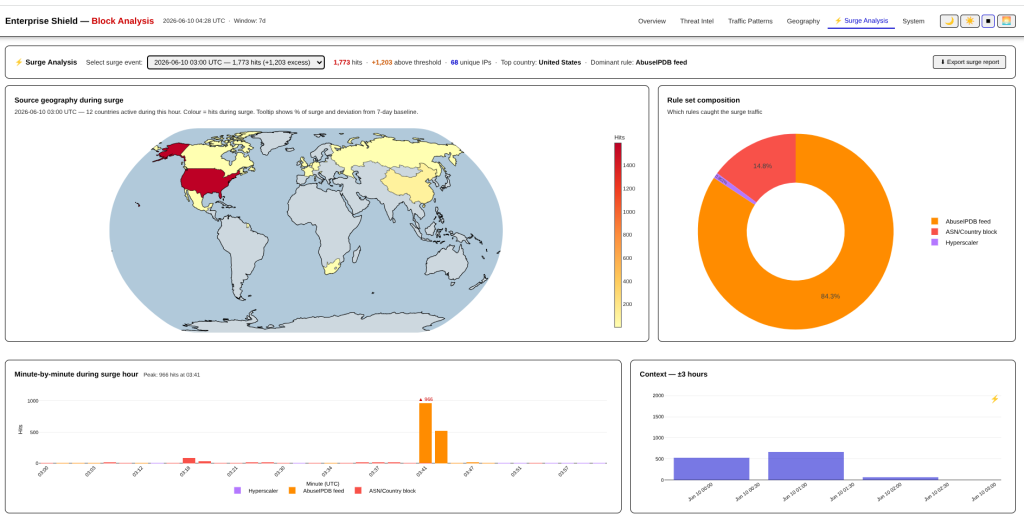
One of the items I iterated through on this was a Surge Analysis, a view into hours when traffic against the firewall was completely off the charts. Well that is starting to bear fruit.
The system has been absolutely hammered today from a number of sources, but most notably slamming into the Hyperscaler ruleset which is more permissive than Azure (that’s a separate nightmare).
These hours are completely out of spec for the system since the reporting system fired up. Taking only the most recent example, the system is designed to show when and where the attacks are coming from and how this traffic relates to traffic for +/- 3h on either side.
But it is also critical to see who is slamming their head into the firewall. In this instance, the surge is completely driven by visitors hiding behind the Cloudflare Warp VPN service. Cloudflare is a part of the Hyperscaler ruleset that begins dropping traffic once a limit for connections per minute is reached.
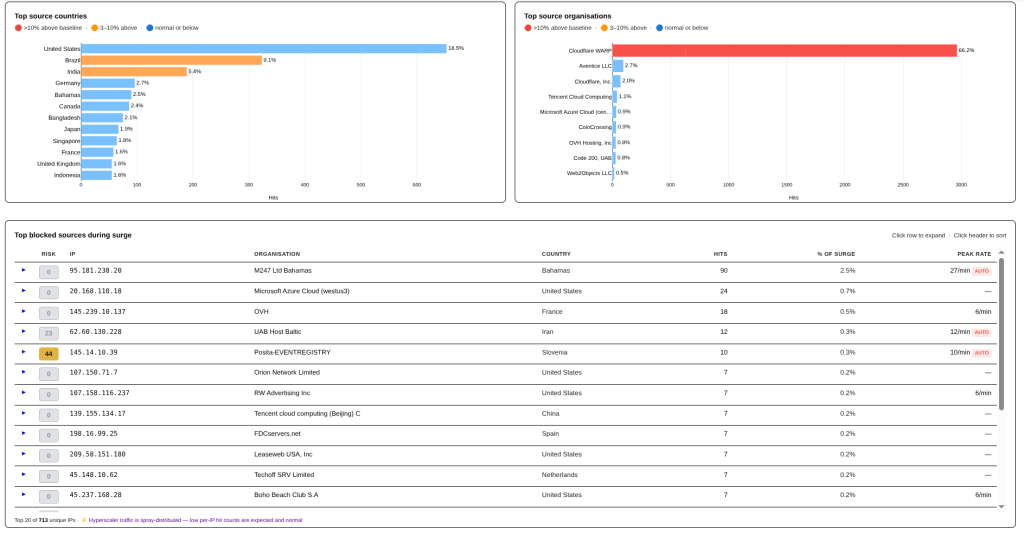
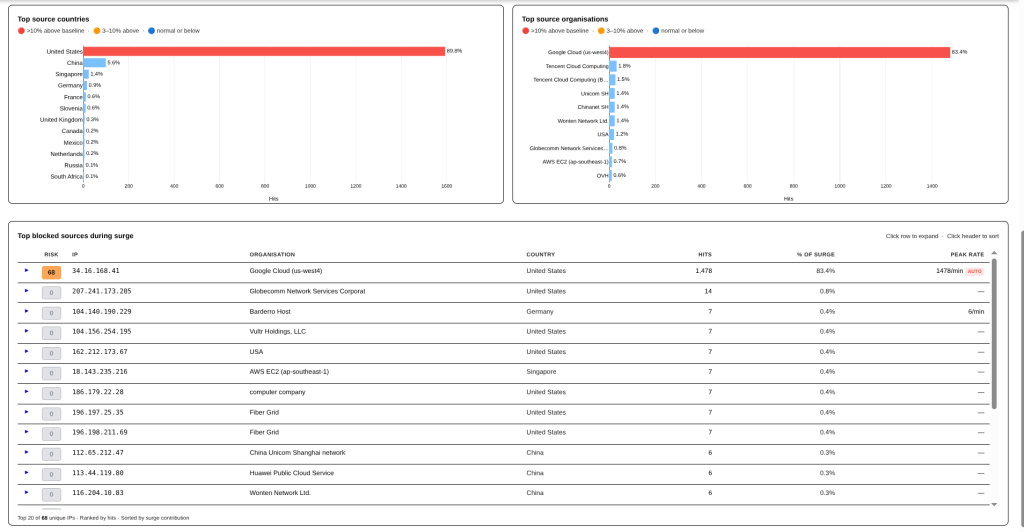
One thing that you will notice is that there is no single Cloudflare Warp IP in the top IP list; this attack is so distributed that it would fall below the detection of individual CIDR block level monitoring.
Another surge shows a completely different source: The AbuseIPDB ruleset. This is based on the top 10K IPs available for adding to rulesets from the AbuseIPDB API.
While smaller in volume, it is very interesting to see that the firewall is able to segment this. This example also shows a mega bot server that drove all of the traffic from a single IP.
It should also be pointed out that this was caught by the AbuseIPDB rules, not the Hyperscaler rules. AbuseIPDB rules precede the Hyperscaler rules for this very purpose: Abusive IPs, regardless of the source, should be blocked.
Overall, this is a very interesting dataset to watch, observing all the attempts to scan, exploit, or attack a single home-hosted web server without a CDN. At this scale for a single server, I appreciate the work that bot mitigation and protection services do for the customers I work with daily.
Now that you have seen the why of Enterprise Shield, this post presents the how. By migrating from a simple set of SHELL scripts and flat files, things get more complex, but also far more manageable and scalable.
Also, by adding in a reporting capability, it is very easy to track who is trying to get in and report on volume, location, network, and type of attack.
1. The Firewall Architecture: Chains and Sets
1.1 How Traffic Flows
Every inbound packet passes through this evaluation sequence before anything else happens. Enterprise Shield inserts itself at position 1 of the INPUT chain, ahead of UFW’s rules.
Critical ordering note:shield_abuseipdb fires before the Azure and hyperscaler rate-limit rules (steps 8-9). This means a known-bad Azure IP is dropped outright rather than merely rate-limited. This was an explicit design decision made during the final production verification.
1.2 The Rate-Limit Chains
Traffic that matches Azure or hyperscaler ipsets is not simply blocked — it would break Bingbot (which runs on AS8075) and legitimate cloud-based monitoring tools. Instead, it flows into dedicated rate-limit chains:
AZURE-RATELIMIT chain
├── hashlimit: 3 connections/minute per source IP, burst 2
├── If within limit: ACCEPT
└── If over limit: DROP + LOG [SHIELD_AZURE_LIMIT]
CLOUD-RATELIMIT chain
├── hashlimit: 20 connections/minute per source IP, burst 8
├── If within limit: ACCEPT
└── If over limit: DROP + LOG [SHIELD_CLOUD_LIMIT]
Azure gets a tighter limit (3/min) because it’s the most frequently abused hyperscaler ASN against this server. AWS/GCP/Oracle/Cloudflare get more headroom (20/min) to accommodate legitimate crawler and monitoring traffic.
Known limitation: HTTP/1.1 keep-alive connections bypass the hashlimit entirely because ESTABLISHED,RELATED packets are accepted at step 1 before they ever reach the rate-limit chains. This is a fundamental iptables constraint, not a bug in Enterprise Shield.
rsyslog matches on [SHIELD_ prefix and routes to /var/log/enterprise_shield/hits.log, which hits_parser.py then consumes every 5 minutes.
2. The Database Schema
The SQLite database is the authoritative state of the entire system. If you have the database, you can reconstruct everything.
2.1 Schema Overview
shield.db
│
├── cidr_blocks ← every CIDR the system manages
├── asn_registry ← all 447+ ASNs with their classification
├── country_registry ← 43 countries with ETag cache
├── abuseipdb_entries ← per-IP AbuseIPDB data, independent lifecycle
├── firewall_hits ← raw parsed hits from rsyslog (rolling window)
├── hits_hourly ← aggregated hourly rollup (long-term storage)
├── ip_enrichment ← per-IP enrichment cache (ip-api.com, Shodan)
├── campaigns ← computed attack campaign groupings (rebuilt each run)
└── system_state ← all runtime state: timestamps, flags, hashes
2.2 cidr_blocks — The Core Table
CREATE TABLE cidr_blocks (
id INTEGER PRIMARY KEY,
cidr TEXT NOT NULL, -- e.g. "185.220.0.0/16"
source TEXT NOT NULL, -- 'asn', 'country', 'manual', 'allow'
source_id TEXT, -- ASN number or country code
ipset_target TEXT NOT NULL, -- which ipset this CIDR belongs to
first_seen INTEGER, -- epoch timestamp
last_verified INTEGER, -- epoch of last successful WHOIS confirm
UNIQUE(cidr, ipset_target)
);
The ipset_target field is what drives the actual ipset membership. When the rebuild runs, it diffs this table against the live ipset state and applies only the delta.
2.3 asn_registry — ASN Classification
CREATE TABLE asn_registry (
asn TEXT PRIMARY KEY, -- 'AS3209', 'AS8075', etc.
name TEXT, -- human-readable name from WHOIS
classification TEXT NOT NULL, -- 'block', 'azure', 'hyperscaler', 'allow'
last_whois INTEGER, -- epoch of last WHOIS lookup
fail_count INTEGER DEFAULT 0, -- consecutive WHOIS failures
note TEXT -- operator annotation
);
The classification field determines which ipset a CIDR ends up in. azure → shield_azure, hyperscaler → shield_hyperscaler, block → shield_block.
2.4 abuseipdb_entries — Separate Lifecycle
CREATE TABLE abuseipdb_entries (
ip TEXT PRIMARY KEY,
abuse_score INTEGER, -- 0-100 confidence score
country_code TEXT,
last_seen TEXT, -- from AbuseIPDB's "lastReportedAt"
refreshed_at INTEGER, -- epoch of our last fetch
in_ipset INTEGER DEFAULT 0 -- currently loaded into shield_abuseipdb?
);
AbuseIPDB entries are refreshed 5× daily (at 00:00, 05:00, 10:00, 15:00, 20:00 UTC) because of the free tier’s rate limit on the blacklist endpoint. The confidence threshold is 90 — only IPs with a score of 90 or above are loaded into the ipset. The table currently holds ~10,000 entries.
2.5 firewall_hits and hits_hourly — The Hit Pipeline
CREATE TABLE firewall_hits (
id INTEGER PRIMARY KEY,
hit_time INTEGER NOT NULL, -- epoch timestamp
src_ip TEXT NOT NULL,
dst_port INTEGER,
protocol TEXT,
shield_tag TEXT, -- SHIELD_BLOCK, SHIELD_ABUSEIPDB, etc.
log_line TEXT -- raw log line for debugging
);
CREATE TABLE hits_hourly (
hour_bucket INTEGER NOT NULL, -- epoch rounded to hour
src_ip TEXT NOT NULL,
shield_tag TEXT NOT NULL,
hit_count INTEGER DEFAULT 0,
PRIMARY KEY (hour_bucket, src_ip, shield_tag)
);
Raw hits accumulate in firewall_hits. The hits_rollup.py job runs at 03:00 daily and aggregates rows older than RAW_RETENTION_DAYS (default: 3 days) into hits_hourly, then deletes the raw rows. hits_hourly retains data for AGGREGATE_RETENTION_DAYS (default: 365 days).
2.6 system_state — No More Flat Files
CREATE TABLE system_state (
key TEXT PRIMARY KEY,
value TEXT
);
-- Key entries:
-- 'last_rebuild_time' : epoch of last successful rebuild
-- 'last_entry_count' : CIDR count at last successful rebuild
-- 'rebuild_in_progress' : '1' if a rebuild is currently running (crash detection)
-- 'last_public_ip' : server's external IP at last rebuild
-- 'config_hash' : SHA-256 of /etc/enterprise_shield/config.conf
-- 'last_abuseipdb_refresh' : epoch of last AbuseIPDB refresh
-- 'hits_parser_position' : byte offset in hits.log (resume parsing from here)
The rebuild_in_progress flag is the crash recovery mechanism. If the system reboots mid-rebuild, restore.py detects this flag on boot and triggers a full rebuild before loading ipsets.
3. The Rebuild Flow
3.1 Nightly Rebuild (shield.py rebuild)
[cron: 30 2 * * *]
│
▼
┌─────────────────────────────────────┐
│ Acquire PID lock │
│ Set rebuild_in_progress = 1 in DB │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ Check config SHA-256 hash │
│ If changed: re-import config file │
│ Destroy any orphan staging ipsets │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ WHOIS refresh (only stale ASNs) │
│ Staleness threshold: 14 days │
│ Typically 2-5 ASNs per night │
│ On failure: keep existing CIDRs, │
│ increment fail_count │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ Country block refresh │
│ ETag conditional GET to GitHub │
│ 304 Not Modified: skip download │
│ 200 OK: parse and update DB │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ Compute delta │
│ DB state vs. live ipset state │
│ Entries to ADD: new CIDRs in DB │
│ Entries to DELETE: removed CIDRs │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ DELTA SAFETY CHECK │
│ New count < (last × 0.95)? │
│ YES → ABORT, preserve current set │
│ NO → proceed │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ Apply delta to staging ipsets │
│ ipset swap staging → live (atomic) │
│ ipset destroy staging sets │
└─────────────────────────────────────┘
│
▼
┌─────────────────────────────────────┐
│ Update DB: │
│ - last_rebuild_time │
│ - last_entry_count │
│ - rebuild_in_progress = 0 │
│ Release PID lock │
└─────────────────────────────────────┘
3.2 The Atomic Swap
The ipset swap is the critical section of the rebuild. The live set is never empty:
shield_block_staging (new CIDRs)
│
│ ipset swap shield_block_staging shield_block
▼
shield_block (now has new CIDRs — atomically)
│
│ ipset destroy shield_block_staging
▼
(staging set gone)
If the swap fails for any reason, the original shield_block is untouched and the staging set is left for cleanup on the next run.
4. The Boot Persistence Architecture
This is one of the most critical (and most debugged) parts of the system. Getting the ordering wrong leaves the server unprotected between reboot and first cron run.
4.1 The Two-Service Boot Sequence
Boot sequence:
kernel loads
│
▼
systemd-modules-load.service ← ensures ip_tables, ip_set kernel modules are loaded
│
▼
local-fs.target ← ensures /var/lib/enterprise_shield/ is mounted
│
▼
enterprise-shield-ipset-restore.service ← runs restore.py --ipsets-only
│ Loads all 7 ipsets from SQLite
│ Sets ipsets before UFW needs them
│
▼
ufw.service ← UFW loads its rules
│ The ipsets now exist when UFW's before.rules references them
│
▼
enterprise-shield-chain-restore.service ← runs restore.py --chains-only
Rebuilds SHIELD-LOGIC, AZURE-RATELIMIT, CLOUD-RATELIMIT chains
Inserts "INPUT -j SHIELD-LOGIC" at position 1
Uses --noflush so UFW's chains are preserved
4.2 Why the Ordering Matters
Service
Must run BEFORE
Must run AFTER
ipset-restore
ufw.service
systemd-modules-load, local-fs.target
chain-restore
(nothing)
ufw.service, ipset-restore
The DefaultDependencies=no setting is not used (a lesson learned from a failed boot cycle) — it was removed too aggressively early and prevented the kernel module loading dependency from being honoured.
4.3 What restore.py Does
# restore.py --ipsets-only
for each ipset in [shield_allow, shield_abuseipdb, shield_block,
shield_penalty, shield_azure, shield_hyperscaler]:
create ipset if not exists
bulk-load CIDRs from cidr_blocks WHERE ipset_target = ipset
# restore.py --chains-only
create SHIELD-LOGIC chain (flush if exists)
add ESTABLISHED/RELATED ACCEPT rule
add loopback ACCEPT rule
add LAN + own IP ACCEPT rule (reads last_public_ip from system_state)
add shield_allow ACCEPT rule
add shield_abuseipdb DROP+LOG rule
add shield_block DROP+LOG rule
add shield_penalty DROP+LOG rule
add shield_azure → AZURE-RATELIMIT rule
add shield_hyperscaler → CLOUD-RATELIMIT rule
create AZURE-RATELIMIT chain with hashlimit rules
create CLOUD-RATELIMIT chain with hashlimit rules
iptables -I INPUT 1 -j SHIELD-LOGIC
4.4 Crash Recovery
If the server loses power mid-rebuild:
Next boot
│
▼
enterprise-shield-ipset-restore.service
│
▼
restore.py checks system_state WHERE key='rebuild_in_progress'
│
├── value = '0': normal restore from DB
│
└── value = '1': CRASH DETECTED
│
▼
Log CRITICAL to /var/log/enterprise_shield/restore.log
Load last known-good CIDRs from DB (last successfully committed state)
Continue with normal restore
Set rebuild_in_progress = 0
The last known-good state is whatever was in the database at the time of the crash. Because the DB commit happens after the ipset swap succeeds, any incomplete rebuild simply means the previous night’s CIDRs are loaded — which is correct behaviour.
5. The Hit Logging Pipeline
iptables LOG rule fires
│
│ Kernel writes to syslog
▼
/var/log/syslog
│
│ rsyslog matches: if $msg contains '[SHIELD_'
▼
/var/log/enterprise_shield/hits.log
│
│ hits_parser.py runs every 5 minutes via cron
│ Resumes from byte offset stored in system_state.hits_parser_position
▼
firewall_hits table (SQLite)
│
│ hits_rollup.py runs at 03:00 daily
│ Aggregates rows older than RAW_RETENTION_DAYS into hits_hourly
│ Deletes aggregated raw rows
▼
hits_hourly table (SQLite)
│
│ deep_shield.py runs every 10 minutes
│ Queries both tables, enriches IPs, computes campaigns
▼
private threat analysis dashboard
│ public_shield.py runs hourly
▼
https://performancezen.com/shield/public_shield.html
(public-facing summary — sanitised, no internal data)
The & stop prevents these messages from also going into /var/log/syslog, keeping the main syslog uncluttered.
5.2 hits_parser.py — Resumable Parsing
The parser reads hits.log from the byte offset stored in system_state.hits_parser_position. On each 5-minute run, it:
Opens the file, seeks to the stored position
Reads all new lines since the last run
Parses each [SHIELD_*] log line for SRC=, DPT=, PROTO=
Inserts rows into firewall_hits
Updates hits_parser_position to the new end-of-file offset
If the log file is rotated (via logrotate), the parser detects the file is smaller than the stored offset and resets to position 0.
6. The AbuseIPDB Integration
AbuseIPDB operates on a completely separate lifecycle from the main rebuild:
[cron: 0 0,5,10,15,20 * * *] (5× daily)
│
▼
abuseipdb.py refresh
│
├── Query AbuseIPDB /api/v2/blacklist
│ Parameters: confidenceMinimum=90, limit=10000
│
├── Parse response → list of {ip, abuseConfidenceScore, countryCode}
│
├── Diff against abuseipdb_entries table:
│ - New IPs: INSERT into table, add to shield_abuseipdb ipset
│ - Removed IPs: DELETE from table, remove from shield_abuseipdb ipset
│ - Unchanged IPs: update refreshed_at timestamp only
│
└── Log summary: X added, Y removed, Z unchanged
The AbuseIPDB ipset (shield_abuseipdb) is kept live-updated between the main nightly rebuilds. A known-bad IP that appears on AbuseIPDB is blocked within 5 hours maximum, without waiting for the 2:30AM rebuild.
7. The Penalty Box
The penalty box (shield_penalty ipset) handles time-limited blocks — typically IPs that have triggered specific application-layer rules or been manually added for investigation.
Adding to penalty box:
shield.py penalty add <ip> [--hours N] (default: 24 hours)
│
├── INSERT into penalty_entries table with expires_at timestamp
└── ipset add shield_penalty <ip>
Expiry check (every 15 minutes via cron):
penalty.py expire
│
├── SELECT from penalty_entries WHERE expires_at < NOW()
├── For each expired entry:
│ ipset del shield_penalty <ip>
│ DELETE from penalty_entries
└── Log: "Expired N penalty entries"
The penalty box also survives reboots — restore.py loads shield_penalty from the database on boot, but only entries whose expires_at is still in the future. Expired entries are not restored.
8. Module Structure
All Python modules live at /usr/local/lib/enterprise_shield/:
Over the years, I have tried to limit the amount of spurious or aggressive traffic against my small, yet mighty web server environment. It started with a list of UFW rules, but that became very unwieldy once the list hit over 25,000 unique CIDR blocks.
A few months ago, working alongside some AI partners, I asked how this system could be made more efficient and manage even larger rulesets without making the server scream in pain every time a large burst of traffic hit it.
That’s when the Enterprise Shield approach was born.
What Is Enterprise Shield?
Enterprise Shield is a custom Linux firewall management system protecting creaky2, a vintage 2008 MacBook Pro repurposed as a personal Ubuntu Server hosting performancezen.com. It is not a product — it is a purpose-built system, grown organically over years of dealing with real-world attacks against a small but publicly visible WordPress blog.
At its core, Enterprise Shield does three things:
Blocks hostile IP space — autonomous systems (ASNs), country CIDR ranges, and individually flagged IPs — before they ever reach the web server.
Rate-limits legitimate but noisy infrastructure — Microsoft Azure, AWS, Google Cloud, Oracle Cloud, Cloudflare — so they can’t hammer the server but aren’t outright blocked.
Logs, enriches, and reports on everything that hits the firewall so you can understand the threat landscape over time.
The system wraps Linux’s ipset and iptables primitives with custom tooling to make them manageable: automating blocklist maintenance, surviving reboots, and providing a real-time terminal dashboard and HTML threat analysis reports.
A Brief History: How We Got Here
The Early Days: Hand-Crafted BASH (v11.x)
Enterprise Shield started as a BASH script. Over time it grew significantly:
ASN blocking via RADB WHOIS lookups, parallelised across threads
AbuseIPDB integration — a penalty box of individually-flagged malicious IPs, refreshed 5× daily (constrained by the free API tier)
Azure and hyperscaler separation — Azure (AS8075) given its own rate-limit chain distinct from AWS/GCP/Oracle/Cloudflare
Atomic ipset swaps — the live blocklist is never empty during an update
Delta safety abort — if the new CIDR count drops >5% from the previous run, the script aborts rather than switching to a degraded ruleset
Systemd boot persistence — two services that restore ipsets and iptables chains after every reboot
By version 11.25-MT, the script was around 500 lines, handled parallel WHOIS with a 4-thread batch model, and managed a blocklist of over 500,000 CIDR entries.
It worked. But it had accumulated significant technical debt.
Why We Rewrote It
Problem 1: Every Run Was a Full Rebuild
The BASH system had no memory between runs. Every night at 2AM:
All ASN WHOIS data was re-fetched — 447 ASNs × a RADB query each, regardless of whether anything had changed
All 43 country CIDR files were re-downloaded from GitHub
All 500,000+ CIDR entries were re-inserted from scratch into a staging ipset
This wasn’t just slow — it was wasteful. ASN CIDR allocations change rarely. The ipverse country files change weekly at most. But the system had no way to say “I already know what AS3209 owns — skip it.”
BASH nightly run cost (approximate):
447 ASN WHOIS lookups ~35 minutes
43 GitHub downloads ~2 minutes
ipset full rebuild ~1 minute
Total rebuild time: ~38 minutes
Total per week: ~4.5 hours of server time
Problem 2: State Was Scattered Across Flat Files
Runtime state was stored in flat files:
/etc/ipset.conf — the full ipset dump (502,575 lines)
/etc/shield-iptables.rules — the iptables chain rules
/var/lib/shield/last_entry_count — just a number, for the delta check
/var/lib/shield/last_public_ip — the server’s external IP at last run
There was no audit trail, no history, no way to answer “what changed between last Tuesday and today?” The last_entry_count file was a single integer — useful for the delta abort check, useless for anything else.
Problem 3: No Hit Data
The BASH system blocked things — but didn’t know what it blocked. There was no structured record of which IPs hit the firewall, when, or how many times. The iptables -L packet counters reset on every rebuild. A threat analysis report was impossible.
Problem 4: AbuseIPDB Was Bolted On
The AbuseIPDB penalty box was a separate script (abuseipdb_penaltybox.sh) that maintained its own ipset (SHIELD_PENALTY), with its own boot persistence service, its own log file, and completely separate state from the main system. It worked, but it was an island.
Problem 5: Boot Persistence Was Fragile
The two-service boot sequence (ipsets before UFW, chains after UFW) worked correctly but relied on /etc/ipset.conf — a 502,575-line flat file. If that file was corrupt or missing, the server came up with no firewall. There was no crash recovery, no verification that the restored state was sane.
The Solution: Python + SQLite
The rewrite was designed around a single guiding principle:
The database is the system. Everything else derives from it.
What Changed
┌────────────────────────────────────────────────────────────-─────────┐
│ BASH v11.25-MT → Python v12 │
├──────────────────────────┬────────────────────────────────-──────────┤
│ State storage │ Flat files → SQLite database │
│ Rebuild strategy │ Full re-fetch → Delta (only changed data) │
│ WHOIS cadence │ Every night for all ASNs → Only stale │
│ Country blocks │ Re-download always → ETag conditional GET │
│ AbuseIPDB │ Separate script/ipset → Integrated table │
│ Hit logging │ None → rsyslog → hits_parser → SQLite │
│ Boot persistence │ Flat file restore → DB-driven restore.py │
│ Crash recovery │ None → rebuild_in_progress flag in DB │
│ Config change detection │ None → SHA-256 hash of config files │
│ Penalty box │ Separate ipset/service → shield_penalty │
│ Allowlist │ Hardcoded in script → shield_allow ipset │
│ Dashboard │ BASH/iptables poll → Python delta packets │
│ Reports │ None → HTML threat analysis reports │
└──────────────────────────┴─────────────────────────────────-─────────┘
The Delta Rebuild Advantage
The most impactful change. Instead of re-fetching everything nightly, the Python system tracks the last successful WHOIS lookup for every ASN and the ETag of every country block file:
Python nightly run cost (approximate):
ASN WHOIS lookups (only stale, 14-day TTL) ~2-5 per night
Country file downloads (only changed, ETag) 0-3 per night (usually 0)
DB diff computation ~5 seconds
ipset delta apply ~10 seconds
Total rebuild time: ~30 seconds typical
Total per week: ~3.5 minutes
That’s roughly a 700× reduction in rebuild time under normal conditions.
The Migration Process
The migration was executed in four phases with no loss of protection at any point.
Phase 1: Database Seeding
↓
Python DB populated while BASH system continues running
Both systems coexist. Python touches no live ipsets.
Phase 2: Shadow Mode (7+ days)
↓
Python rebuild runs with --dry-run flag
Logs all changes it WOULD make, modifies nothing
Compared against BASH output each morning
Phase 3: Cutover
↓
BASH cron entries commented out (not deleted)
Python cron entries go live
New systemd boot services enabled
72-hour intensive monitoring period
Phase 4: Cleanup (30 days later)
↓
BASH scripts archived to tar.gz
Old flat files removed
502,575-line /etc/ipset.conf deleted
Orphan ipsets destroyed
Old systemd services masked
What Was Decommissioned
The cutover removed a significant amount of legacy infrastructure:
/usr/local/bin/enterprise_shield.sh (the main BASH script)
/usr/local/bin/block_asn.sh (the injection tool)
/usr/local/bin/abuseipdb_penaltybox.sh
/usr/local/bin/shield-stat.sh and shield_display.sh
/etc/ipset.conf — 502,575 lines, gone
shield-ipset-restore.service (BASH-era)
shield-iptables-restore.service (BASH-era)
The orphan SHIELD_PENALTY ipset that had survived via netfilter-persistent
The new Python system replaced all of this with a clean installation under /usr/local/lib/enterprise_shield/, state in /var/lib/enterprise_shield/shield.db, and configuration in /etc/enterprise_shield/.
Key Decisions Made Along the Way
Several non-obvious architectural choices shaped the Python system. These are worth documenting because they affected behaviour:
Hard DELETEs over soft deletes — Earlier design drafts used a soft-delete pattern (marking rows inactive rather than removing them). This was rejected: it causes the database to grow indefinitely, and there’s no useful recovery scenario where you’d want to un-delete a stale CIDR entry. The Python system uses hard DELETEs.
AbuseIPDB gets its own table — The initial design merged AbuseIPDB IPs into the main cidr_blocks table. This was wrong: AbuseIPDB operates on a completely different lifecycle (5× daily refresh, IP-level not CIDR-level, confidence threshold filtering). It got its own abuseipdb_entries table with independent process ownership.
ip-api.com not BGPView — Report enrichment (ASN name, country, city for attacker IPs) originally used BGPView. This was replaced with ip-api.com: 45 req/min free tier, no auth, returns ASN + org + country + city in a single call. Shodan’s InternetDB (internetdb.shodan.io/{ip}) was added for open port data and threat tags — also no auth.
All runtime state in the database — No flat files for parser position, public IP cache, or rebuild flags. The system_state table in SQLite holds everything. This means the database backup is the complete system backup.
SHA-256 config change detection — The rebuild checks a SHA-256 hash of the config files at startup. If anything changed since the last run, a full re-import of config is triggered automatically. No manual --import step needed.
The Result
Enterprise Shield v12 reached verified production status on 2026-05-27, after extensive testing including multiple reboot verification cycles. All 16 items on the post-reboot checklist pass cleanly.
The system now:
Rebuilds in ~30 seconds instead of ~38 minutes
Has a complete history of every CIDR change
Logs every firewall hit to a structured database
Produces HTML threat analysis reports
Survives reboots with a DB-driven restore rather than a flat-file restore
Has crash recovery via the rebuild_in_progress flag
Provides a real-time terminal dashboard (shield_stat.py) with delta-based packet rate bars
The database contains ~500,000 active CIDR entries across 7 ipsets, ~10,000 AbuseIPDB entries, and growing hit log data as the rsyslog pipeline feeds it.
The next post will go into the architecture of the system so that if you’re considering implementing something similar, you can see how to configure the entire flow.
For those who are interested, here is the current the ASN Block List that is used in my local server firewall setup. Let me know if you think of some that should be added; or if you are on the list and you don’t think you should be!
=========================================================================== ENTERPRISE SHIELD: AUTONOMOUS SYSTEM NUMBER (ASN) INTEL PROFILE ===========================================================================
[STATUS KEY] [BLOCK] Active Firewall Mitigation (Traffic dropped at edge) [REVIEW] Deactivated/Bypassed (High collateral damage risk, requires audit)
--------------------------------------------------------------------------- 1. TRANSIT / BACKBONE NETWORKS (High Risk of Downstream Collateral Damage) --------------------------------------------------------------------------- ASN STATUS GEOGRAPHY PROVIDER / CONTEXT 174 [BLOCK] US Cogent Communications - Major transit backbone 1299 [BLOCK] SE Arelion Sweden AB - Tier 1 backbone 3209 [BLOCK] DE Vodafone Germany - Regional infrastructure 3257 [BLOCK] US GTT Communications Inc. - Global carrier 6939 [BLOCK] US Hurricane Electric - Large transit network 7979 [BLOCK] Global SoftLayer / IBM Cloud 11042 [BLOCK] US Network Transit Holdings LLC
--------------------------------------------------------------------------- 2. CHINESE STATE CARRIERS & EAST ASIAN TECH GIANTS --------------------------------------------------------------------------- ASN STATUS GEOGRAPHY PROVIDER / CONTEXT 4134 [BLOCK] CN ChinaNet - China Telecom primary backbone 4811 [BLOCK] CN China Telecom (Group) - Shanghai MAN 4831 [BLOCK] CN China Telecom (CTTNET) - Core state carrier 4837 [BLOCK] CN China Unicom (CNC Group) - Industrial state line 9808 [BLOCK] CN China Mobile Communications Group Co., Ltd. 24445 [BLOCK] CN Henan Mobile Communications Co. Ltd 37963 [BLOCK] CN Alibaba Cloud (Aliyun) - Mainland China clusters 38365 [BLOCK] CN Baidu - Beijing Netcom Science & Tech 45102 [BLOCK] APAC Alibaba Cloud APAC infrastructure node 58461 [BLOCK] CN CT-HangZhou-IDC 63199 [BLOCK] CN/HK CDS Global Cloud Co., Ltd 132203 [BLOCK] CN Tencent Cloud compute infrastructure 135354 [BLOCK] SG NAVER Business Platform Asia Pacific Pte. Ltd. 136907 [BLOCK] CN Huawei Cloud computing platforms 138699 [BLOCK] SG/CN TikTok Pte. Ltd. application edge ingestion 211443 [BLOCK] HK Sino Worldwide Trading Limited proxy ingress 213802 [BLOCK] HK TF - Tianfeng Communications Limited 214669 [BLOCK] HK Starlight Tech Trading Co. Limited 396986 [BLOCK] US/CN Bytedance Inc. platforms crawler edge 55933 [BLOCK] HK CLOUDIE-AS-AP - Cloudie Limited
--------------------------------------------------------------------------- 4. CENTRAL ASIA INFRASTRUCTURE --------------------------------------------------------------------------- ASN STATUS GEOGRAPHY PROVIDER / CONTEXT 8193 [BLOCK] UZ Uzbektelekom Joint Stock Company state carrier 8200 [BLOCK] KZ Uplink LLC commercial broadband backbone 35682 [BLOCK] UZ Best Internet Solution alternative host 48716 [BLOCK] KZ PS Internet Company LLP web & cloud host 203044 [BLOCK] KZ Telepatiya Ltd virtualization platform 210006 [BLOCK] KZ Shereverov Marat Ahmedovich private register 210976 [BLOCK] KZ Timeweb LLP shared hosting/VPS cluster
--------------------------------------------------------------------------- 5. EASTERN EUROPE / UKRAINE / BALTICS --------------------------------------------------------------------------- ASN STATUS GEOGRAPHY PROVIDER / CONTEXT 24651 [BLOCK] LV JSC BALTICOM regional internet provider 30860 [BLOCK] UA Virtual Systems LLC high-privacy offshore VPS 42159 [BLOCK] UA Zemlyaniy Dmitro Leonidovich private operator 61424 [BLOCK] SK ESERVER-SK-AS - eServer s.r.o. professional host 204957 [BLOCK] UA GREEN FLOID LLC corporate cloud cluster 211736 [BLOCK] UA FOP Dmytro Nedilskyi commercial network
--------------------------------------------------------------------------- 6. MIDDLE EAST & LEVANT --------------------------------------------------------------------------- ASN STATUS GEOGRAPHY PROVIDER / CONTEXT 8697 [BLOCK] JO Jordan Telecommunications PSC routing core 9038 [BLOCK] JO/BH BATELCO / Al Bahrainia al Urdunia multi-transit 202670 [BLOCK] UAE CLOUDZME FZE free-zone hosting arrays 206446 [BLOCK] IL CLOUD LEASE Ltd specialized provisioning 211273 [BLOCK] UAE csoft - Cloud Software FZCO (US footprint)
--------------------------------------------------------------------------- 7. TURKEY (REGIONAL BACKBONES & DATACENTERS) --------------------------------------------------------------------------- ASN STATUS GEOGRAPHY PROVIDER / CONTEXT 9121 [BLOCK] TR TTNet - Turk Telekomunikasyon Anonim Sirketi 12735 [BLOCK] TR TurkNet major independent high-speed ISP 205733 [BLOCK] TR HOSTIFOX Bilisim Hizmetleri game server VPS 208913 [BLOCK] TR Kitsune Bilisim Sistemleri platform space 211557 [BLOCK] TR TAYNET TEKNOLOJI TICARET LTD server housing 212193 [BLOCK] TR VIVA INTERNET LIMITED SIRKETI (Active attack) 213407 [BLOCK] TR Uzmansoft Bilisim Web Yazilim Hizmetleri 213488 [BLOCK] TR Inoxweb Datacenter ve Hosting colocation center 214000 [BLOCK] TR Voxnet Bilisim Teknolojileri delivery platform
--------------------------------------------------------------------------- 8. CLOUD / HYPERSCALER INFRASTRUCTURE (B2B Integrations Impact Risk) --------------------------------------------------------------------------- ASN STATUS GEOGRAPHY PROVIDER / CONTEXT 2639 [BLOCK] Global Zoho Corporation business CRM/mail endpoints 8075 [REVIEW] Global Added to AZURE-RATELIMIT rule List 14618 [REVIEW] US Added to CLOUD-RATELIMIT rule List 16509 [REVIEW] Global Added to CLOUD-RATELIMIT rule List 31898 [REVIEW] Global Added to CLOUD-RATELIMIT rule List 63949 [REVIEW] US Added to CLOUD-RATELIMIT rule List 208172 [BLOCK] CH Proton AG privacy email/VPN endpoint 395747 [REVIEW] US Added to CLOUD-RATELIMIT rule List 396982 [REVIEW] Global Added to CLOUD-RATELIMIT rule List
**Note:** Main Google Search crawler (AS15169) is fully whitelisted.
--------------------------------------------------------------------------- 9. SOCIAL MEDIA PLATFORMS CRAWLER INGRESS --------------------------------------------------------------------------- ASN STATUS GEOGRAPHY PROVIDER / CONTEXT 32934 [BLOCK] US Facebook Inc. (Meta) crawler asset block 1 54115 [BLOCK] US Facebook Inc. (Meta) crawler asset block 2 63293 [BLOCK] US Facebook Inc. (Meta) crawler asset block 3
--------------------------------------------------------------------------- 10. EUROPEAN HOSTING & VPS PROVIDERS --------------------------------------------------------------------------- ASN STATUS GEOGRAPHY PROVIDER / CONTEXT 1101 [BLOCK] NL IP-EEND BV commercial cloud block 3920 [BLOCK] EE PUSHPKT OU (Note: Mislabeled as RIPE NCC) 6724 [BLOCK] DE Strato GmbH consumer web host & storage 8560 [BLOCK] DE IONOS SE / 1&1 European business host cloud 8896 [BLOCK] NO GlobalConnect AS strategic transport core 9009 [BLOCK] UK/EU M247 Europe low-cost multi-region nodes 12488 [BLOCK] UK Krystal Hosting Ltd green cloud shared app 12552 [BLOCK] SE GlobalConnect AB high capacity transit 12574 [BLOCK] DE Hosting.de GmbH regional cloud infrastructure 12816 [BLOCK] DE Leibniz-Rechenzentrum university research node 12876 [BLOCK] FR Scaleway SAS cloud developer instances 13213 [BLOCK] UK UK-2 Limited / Iomart corporate web clusters 14576 [BLOCK] EU Hosting Solution Ltd. general multi-tenant host 14670 [BLOCK] UK WHG Hosting Services Ltd engine (4 of 4) 15967 [BLOCK] PL Nazwa.pl Sp.z.o.o. domestic enterprise cloud 16276 [BLOCK] FR OVHcloud largest European host (high bot density) 20738 [BLOCK] UK Heart Internet Ltd legacy reseller platform 20857 [BLOCK] NL TransIP BV / Signet B.V. cloud cluster (2 of 2) 20860 [BLOCK] UK IOMART Cloud Services Limited business servers 21499 [BLOCK] DE Host Europe GmbH managed web node matrix 24768 [BLOCK] PT ALMOUROLTEC Servicos informatics management node 24940 [BLOCK] DE Hetzner Online GmbH core machine node (1 of 3) 24961 [BLOCK] DE/CH WIIT AG premium enterprise cloud engine 26141 [BLOCK] EU CubePath unmapped cloud network pathways 28753 [BLOCK] DE Leaseweb Deutschland GmbH throughput host 29066 [BLOCK] DE/FR velia.net Internetdienste GmbH unmanaged iron 29222 [BLOCK] CH Infomaniak Network SA eco-friendly cloud core 29522 [BLOCK] PL Cyber_Folks S.A. hosting group array (CF-KRK) 29550 [BLOCK] UK SIMPLYTRANSIT Team Blue Carrier transit 30781 [BLOCK] FR Free Pro SAS corporate broadband hosting 30823 [BLOCK] DE aurologic GmbH specialized colocation housing 30893 [BLOCK] SE No ACK Group Holding AB dense dev clusters 31034 [BLOCK] IT Aruba S.p.A. dominant consumer & enterprise host 31229 [BLOCK] PL Beyond.pl sp. z o.o. Tier III datacenter 34081 [BLOCK] DE/IT INCUBATEC GmbH - Srl corporate app host 34360 [BLOCK] PL Cyber_Folks S.A. hosting group array (OGICOM) 34549 [BLOCK] DE meerfarbig GmbH & Co. KG agile testing staging 35470 [BLOCK] NL Signet B.V. Dutch cloud cluster (1 of 2) 35779 [BLOCK] RS mCloud doo dynamic SSD virtual systems 39122 [BLOCK] IE Blacknight Internet Solutions registrar host 39351 [BLOCK] SE 31173 Services AB commercial VPN exit routes 39392 [BLOCK] CZ SH.cz s.r.o. / SuperNetwork aggregation node 39572 [BLOCK] NL DataWeb Global Group B.V. SLA enterprise fiber 39704 [BLOCK] NL CJ2 Hosting B.V. regional multi-server housing 41564 [BLOCK] UK Orion Network Limited computing node (1 of 2) 41608 [BLOCK] ES NextGenWebs S.L. consumer web host server 42525 [BLOCK] DE GlobalConnect A/S northern European fiber 42708 [BLOCK] SE Portlane AB unmanaged raw data transport 42831 [BLOCK] UK UK Dedicated Servers Limited bare-metal systems 43037 [BLOCK] CZ Seznam.cz a.s. domestic search engine crawler 43289 [BLOCK] MD Trabia SRL offshore datacenter proxy target 43350 [BLOCK] NL NForce Entertainment BV high-bandwidth stream 43357 [BLOCK] UK Owl Limited corporate platform route block 43578 [BLOCK] ES bitNAP carrier neutral colocation facility 43641 [BLOCK] PL Sollutium EU Sp. z o.o. custom network assets 44477 [BLOCK] MD PQ Hosting Plus S.R.L. Stark Industries affiliate 44803 [BLOCK] DK Webdock.io ApS lightweight developer VPS frame 46805 [BLOCK] UK Angelnet Limited cloud infrastructure (4 of 4) 47544 [BLOCK] PL IQ PL Sp. z o.o. transaction performance host 47583 [BLOCK] LT Hostinger International global shared host matrix 48024 [BLOCK] EU NEROCLOUD LTD privacy-centric hosting arrays 48047 [BLOCK] PL Krakowskie Centrum Przetwarzania regional node 48057 [BLOCK] MK ITV DOOEL Skopje multi-tenant infrastructure 48090 [BLOCK] EU TECHOFF SRV LIMITED offshore cloud compute 48137 [BLOCK] NL PI-GROUP BV network infrastructure system 48505 [BLOCK] PL Kylos sp. z o.o. localized development spaces 48854 [BLOCK] DK team.blue Denmark A/S application cloud space 49453 [BLOCK] NL Global Layer BV mass raw bandwidth platform 49592 [BLOCK] UK Pipe Networks LTD datacenter transport links 49635 [BLOCK] ES Cloudi Nextgen SL automated virtualization 49683 [BLOCK] UK MASSIVEGRID LTD high availability platform 49981 [BLOCK] NL WorldStream B.V. low-cost commodity iron housing 50300 [BLOCK] UK CustodianDC Limited eco-efficient server space 50304 [BLOCK] NO Blix Solutions AS customized server housing 50599 [BLOCK] PL DATASPACE P.S.A. scalable compute clusters 50926 [BLOCK] ES AXARNET Comunicaciones S.L. managed systems 51167 [BLOCK] DE Contabo GmbH high density developer VMs provider 51396 [BLOCK] DE Pfcloud UG boutique private cloud frames 51430 [BLOCK] NL AltusHost B.V. managed business host arrays 51852 [BLOCK] CH Private Layer INC offshore bulletproof net 51859 [BLOCK] RS Mainstream doo Beograd corporate hosting grid 56322 [BLOCK] HU ServerAstra Kft. privacy cloud servers ecosystem 57043 [BLOCK] NL HOSTKEY B.V. scraping automation compute block 57858 [BLOCK] UK Angelnet Limited cloud infrastructure (3 of 4) 58065 [BLOCK] UK Orion Network Limited computing node (2 of 2) 59651 [BLOCK] Global AS QualityNetwork global transport pathways 59943 [BLOCK] BE Level 27 BVBA managed app staging clouds 60068 [BLOCK] Global CDN77 / Datacamp Limited massive distribution CDN 60223 [BLOCK] UK Netiface international deployment grid (2 of 3) 60404 [BLOCK] NL Liteserver NVMe high performance virtual environments 60781 [BLOCK] NL LeaseWeb Netherlands BV data distribution core 60798 [BLOCK] IT Servereasy Srl agile Linux hosting frames 62240 [BLOCK] UK Clouvider Ltd colocation host space (2 of 2) 63119 [BLOCK] UK Angelnet Limited cloud infrastructure (2 of 4) 133944 [BLOCK] LT trafficforce UAB high-volume traffic node (2 of 2) 141995 [BLOCK] APAC Contabo Asia Private Limited developer clouds 197540 [BLOCK] DE netcup GmbH consumer cloud systems platform 198139 [BLOCK] DE Lucas Vossberg private independent routing 199524 [BLOCK] LU G-Core Labs S.A. global edge CDN infrastructure 199404 [BLOCK] UK WHG Hosting Services Ltd engine (2 of 4) 200019 [BLOCK] MD ALEXHOST SRL anonymous bulletproof web host 201341 [BLOCK] LT trafficforce UAB high-volume traffic node (1 of 2) 201579 [BLOCK] UK HostGnome Ltd budget Windows/Linux NVMe VPS 201814 [BLOCK] PL MEVSPACE sp. z o.o. efficient bare metal iron 203446 [BLOCK] UK Smartnet Limited business production host 203476 [BLOCK] FR GANDI SAS web registrar and cluster workspace 203516 [BLOCK] UK/DE AltunHOST LTD distributed game server system 204240 [BLOCK] EU REXE localized system virtualization endpoint 204646 [BLOCK] DE web2objects GmbH e-commerce dev sandboxes 204770 [BLOCK] LT UAB Cherry Servers cloud developer host (1 of 2) 204800 [BLOCK] UK WHG Hosting Services Ltd engine (3 of 4) 205948 [BLOCK] DE creoline GmbH premium SSD cluster arrays 206092 [BLOCK] UK F.N.S. Holdings Limited infrastructure assets 206238 [BLOCK] EU Unknown European Provider - Direct audit recommended 206264 [BLOCK] EU Amarutu Technology Ltd offshore routing profile 206305 [BLOCK] RO SC ITNS.NET SRL regional datacenter pathways 206892 [BLOCK] HU Rendszerinformatika Zrt. corporate applications 206996 [BLOCK] DE ZAP-Hosting GmbH automated rental game cloud 207179 [BLOCK] NL WilroffReitsma B.V. managed IT workspace cloud 207567 [BLOCK] EU Intezio Worldwide Limited proxy provisioning 207569 [BLOCK] UK I-SERVERS LTD direct-access environment hosting 207957 [BLOCK] UK Serv.Host Group Ltd wholesale virtual machines 208046 [BLOCK] FR KOGLER Gabin private boutique developer lab 208137 [BLOCK] RO Feo Prest SRL localized routing nodes network 209242 [BLOCK] UK Clouvider Ltd colocation host space (1 of 2) 209373 [BLOCK] CH/Global SWISSNET LLC secure corporate cloud network 209605 [BLOCK] LT UAB Host Baltic regional server configurations 209709 [BLOCK] LT UAB code200 dynamic testbeds framework (1 of 2) 209847 [BLOCK] NL WorkTitans B.V. SaaS developer sandbox iron 210403 [BLOCK] FR Groupe LWS SARL consumer web & shared compute 210457 [BLOCK] EU Kyonix Networks Limited server array optimizations 210558 [BLOCK] DE 1337 Services GmbH privacy anonymous proxy node 210743 [BLOCK] FR BABBAR-AS - Babbar SAS framework systems 210785 [BLOCK] DE KAPELAN Medien GmbH digital media crawlers 210906 [BLOCK] LT UAB Bite Lietuva domestic broadband carrier 211298 [BLOCK] UK Driftnet Ltd active security honey-scanner 211381 [BLOCK] LV/NL Podaon SIA cross-border virtual computing 211590 [BLOCK] FR Bucklog SARL micro-node VPS structures 212220 [BLOCK] SE Kepler Technologies AB automated virtual arrays 212238 [BLOCK] Global Datacamp Limited multi-region CDN delivery 212286 [BLOCK] UK LonConnect Ltd metropolitan interconnection 212317 [BLOCK] DE Hetzner Online GmbH performance engine (3 of 3) 213230 [BLOCK] DE Hetzner Online GmbH performance engine (2 of 3) 213535 [BLOCK] EU YottaSrc dynamic on-demand system hosting 213702 [BLOCK] UK QWINS LTD web automation staging nodes 213755 [BLOCK] EU LUNORY CLOUD SOLUTIONS LTD flexible structures 213790 [BLOCK] EU Limited Network LTD virtual testing ranges 213887 [BLOCK] UK WAIcore Ltd AI-oriented acceleration clusters 213896 [BLOCK] LT UAB Cherry Servers cloud developer host (2 of 2) 214238 [BLOCK] UK HOST TELECOM LTD enterprise cloud engine 214503 [BLOCK] SE QuxLabs AB advanced networking lab systems 214716 [BLOCK] UK WEYRO LTD corporate computing platforms 214902 [BLOCK] DK Philip Fjaera PFWeb Solutions micro hosting 215125 [BLOCK] NL Church of Cyberology high privacy proxy nodes 215439 [BLOCK] EU PLAY2GO INTERNATIONAL LTD app environments 215540 [BLOCK] UK Global Connectivity Solutions multi-transit 215730 [BLOCK] EU H2NEXUS LTD technical system virtualization 215747 [BLOCK] NL NubaCloud B.V. emerging platform architecture 202412 [BLOCK] EU Omegatech LTD high density framework grids
--------------------------------------------------------------------------- 11. LEASEWEB GROUP CONSOLIDATED INFRASTRUCTURE --------------------------------------------------------------------------- ASN STATUS GEOGRAPHY PROVIDER / CONTEXT 7203 [BLOCK] US Leaseweb USA Inc. enterprise compute (4 of 7) 19148 [BLOCK] US Leaseweb USA Inc. enterprise compute (5 of 7) 27411 [BLOCK] US Leaseweb USA Inc. enterprise compute (6 of 7) 30633 [BLOCK] US Leaseweb USA enterprise compute (1 of 7) 32613 [BLOCK] CA Leaseweb Canada Inc. regional distribution hub 393886 [BLOCK] US Leaseweb USA Inc. enterprise compute (7 of 7) 394380 [BLOCK] US Leaseweb USA Inc. enterprise compute (3 of 7) 395954 [BLOCK] US Leaseweb USA enterprise compute (2 of 7) 396190 [BLOCK] US Leaseweb USA Inc. enterprise compute (8 of 7) 396362 [BLOCK] US Leaseweb USA enterprise compute (3 of 3)
--------------------------------------------------------------------------- 12. GMO INTERNET GROUP / SAKURA (JAPAN) --------------------------------------------------------------------------- ASN STATUS GEOGRAPHY PROVIDER / CONTEXT 7506 [BLOCK] JP INTERQ - GMO Internet Group Inc. flagship hub 7684 [BLOCK] JP SAKURA Internet Inc. cloud clusters (2 of 2) 9370 [BLOCK] JP SAKURA Internet Inc. cloud clusters (1 of 2) 58791 [BLOCK] JP GMO Internet Group Inc. regional infrastructure 131921 [BLOCK] JP GMO GlobalSign Holdings K.K. identity routing 131965 [BLOCK] JP Xserver Inc. high density shared web hosting
--------------------------------------------------------------------------- 13. US & NORTH AMERICAN HOSTING / VPS PROVIDERS --------------------------------------------------------------------------- ASN STATUS GEOGRAPHY PROVIDER / CONTEXT 7393 [BLOCK] US CYBERCON INC. industrial colocation server yard 7489 [BLOCK] US HostUS virtual machine provisioning clusters 9115 [BLOCK] CA Internet Names for Business Inc. (1 of 2) 10439 [BLOCK] US CariNet Inc. unmanaged bare-metal iron tracks 10557 [BLOCK] US Connect Northwest Internet Services LLC 11320 [BLOCK] US LightEdge Solutions compliant continuity center 11706 [BLOCK] US Telefônica Brasil S.A (US asset structures) 11878 [BLOCK] US tzulo inc. high bandwidth dedicated server fields 13332 [BLOCK] US Hype Enterprises software hosting frameworks 13768 [BLOCK] CA Aptum Technologies hybrid cloud systems 14061 [BLOCK] US DigitalOcean LLC developer cloud droplets 14131 [BLOCK] US DataYard managed enterprise network hosting 14555 [BLOCK] US LiquidNet US LLC reseller app hosting frames 14956 [BLOCK] US RouterHosting LLC custom VPS provisioning 15003 [BLOCK] US Nobis Technology Group high performance nodes 16628 [BLOCK] US DedFiberCo point-to-point data links 18450 [BLOCK] US WebNX Inc. extreme performance high cooling host 18501 [BLOCK] US CyberCloud Professionals LLC corporate staging 18779 [BLOCK] US EGIHosting wholesale unmanaged server arrays 19084 [BLOCK] US ColoUp regional colocation & rack operations 19318 [BLOCK] US Interserver Inc. standard low-cost shared cloud 20278 [BLOCK] US Nexeon Technologies Inc. internet transit node 20473 [BLOCK] US Vultr / AS-CHOOPA on-demand global hardware 21769 [BLOCK] US Colocation America Corporation secure data rooms 21859 [BLOCK] US Zenlayer Inc. boundary acceleration cloud (1 of 2) 22295 [BLOCK] US Advin Services LLC lightweight virtual arrays 22611 [BLOCK] US InMotion Hosting Inc. web optimized core (1 of 2) 22612 [BLOCK] US Namecheap Inc. shared hosting & infrastructure 23033 [BLOCK] US Wowrack.com global managed cloud systems 23470 [BLOCK] US ReliableSite.Net LLC dedicated DDoS limited iron 25820 [BLOCK] CA IT7 Networks Inc. systems automation endpoints 26347 [BLOCK] US DreamHost mainstream web properties space 26464 [BLOCK] US Joyent Inc. container-native computing environments 26496 [BLOCK] US GoDaddy.com LLC retail consumer web hosts core 26548 [BLOCK] US PureVoltage Hosting Inc. customized server racks 27257 [BLOCK] US Webair Internet Development medical cloud grids 27589 [BLOCK] US MOJOHOST high throughput media streaming engine 29802 [BLOCK] US HIVELOCITY Inc. bare metal compute spaces (1 of 2) 29873 [BLOCK] US Newfold Digital Inc. parent host brand pool 30058 [BLOCK] US FDCservers.net cheap unmetered bandwidth lines 30447 [BLOCK] CA Internet Names For Business Inc. (2 of 2) 32244 [BLOCK] US Liquid Web LLC managed premium corporate host 32489 [BLOCK] CA Amanah Tech Inc. secure offshore Canadian vault 33182 [BLOCK] US HostDime.com Inc. global edge execution clusters 35916 [BLOCK] US Multacom Corporation advanced engineering hosts 36007 [BLOCK] US Kamatera Inc. modular hourly billed global cloud 36352 [BLOCK] US ColoCrossing high density unmanaged budget cells 36680 [BLOCK] US Netiface LLC international deployment grid (1 of 3) 40021 [BLOCK] US Contabo Inc. North American arm of Contabo cloud 40065 [BLOCK] US CNSERVERS LLC intelligent data delivery tracks 40300 [BLOCK] US DR Fortress LLC mid-Pacific Hawaiian transit hub 40676 [BLOCK] US Psychz Networks active line filtering nodes 46261 [BLOCK] US QuickPacket LLC budget hardware deployment arrays 46475 [BLOCK] US Limestone Networks Inc. solid-state cloud iron 46562 [BLOCK] US Performive LLC mid-market operational environments 46606 [BLOCK] US UNITAS Global software defined access routes 46844 [BLOCK] US Sharktech original heavy scrubbing DDoS limits 46918 [BLOCK] US GlobalHostingSolutions Inc. safe compute environments 46995 [BLOCK] US Jump Wireless LLC wireless data edge cells 50219 [BLOCK] US Valence Technology Co. software testbeds 53667 [BLOCK] US FranTech Solutions / BuyVM budget storage slabs 53755 [BLOCK] US Input Output Flood LLC raw compute engine iron 54600 [BLOCK] US PEG TECH INC broad distribution network spaces 54641 [BLOCK] US InMotion Hosting Inc. web optimized core (2 of 2) 55286 [BLOCK] US B2 Net Solutions / ServerCheap budget VMs set 51317 [BLOCK] US Hivelocity LLC bare metal compute spaces (2 of 2) 62468 [BLOCK] US VpsQuan L.L.C. offshore-facing virtualization 62610 [BLOCK] US Zenlayer Inc. boundary acceleration cloud (2 of 2) 62874 [BLOCK] US Web2Objects LLC corporate app deployment fields 62904 [BLOCK] US Eonix Corporation efficient distributed system pods 63023 [BLOCK] US GTHost instant bare metal hardware nodes 63150 [BLOCK] US BAGE CLOUD LLC developer micro testing nodes 63410 [BLOCK] US PrivateSystems Networks isolation security grids 64200 [BLOCK] US VIVID-HOSTING LLC performance customized grids 64249 [BLOCK] US Charles River Operation private computing segments 64267 [BLOCK] US Sprious LLC automated scraping residential proxy 64286 [BLOCK] US LogicWeb Inc. integrated security host platform 149042 [BLOCK] US Silicon Cloud Global trans-Pacific business paths 150303 [BLOCK] US SoloRDP Indian firm - US registered desktop host 202425 [BLOCK] US IP Volume Inc. bulk asset allocation blocks 209372 [BLOCK] US WS Telecom Inc enterprise carrier alternative 214036 [BLOCK] US Ultahost Inc. fast virtual machine chains 399275 [BLOCK] US Solid Systems LLC industrial infrastructure maps 394474 [BLOCK] US WhiteLabelColo unbranded data room leasing blocks 396073 [BLOCK] US Majestic Hosting Solutions LLC cloud instances 396356 [BLOCK] US Latitude.sh API-driven metal automation provider 396998 [BLOCK] US Path Network Inc. Anycast DDoS scrubbing line 397423 [BLOCK] US Tier.Net Technologies LLC storage room arrays 398019 [BLOCK] US Dynu Systems Incorporated dynamic infrastructure 398781 [BLOCK] US Oculus Networks Inc. VR heavy compute sandboxes 399073 [BLOCK] US BUNNY TECHNOLOGY LLC fast static asset CDN 399629 [BLOCK] US BL Networks fast transaction environments 399804 [BLOCK] US Hostodo low-end storage proxy nodes 400587 [BLOCK] US Ryamer LLC script execution automation cells 400940 [BLOCK] US Railway container-native cloud PaaS structures 401152 [BLOCK] US Ace Data Centers II LLC high density yards 401626 [BLOCK] US Netiface America Inc. deployment grid (3 of 3) 401696 [BLOCK] US cognetcloud INC enterprise application space
--------------------------------------------------------------------------- 14. LATIN AMERICAN CARRIERS & HOSTING INFRASTRUCTURE --------------------------------------------------------------------------- ASN STATUS GEOGRAPHY PROVIDER / CONTEXT 1916 [BLOCK] BR Rede Nacional de Ensino e Pesquisa academic net 17222 [BLOCK] BR Mundivox do Brasil Ltda corporate fiber fields 26599 [BLOCK] BR Telefônica Brasil S.A. national broadband lines 28573 [BLOCK] BR Claro NXT Telecomunicacoes Ltda mobile data switching 53107 [BLOCK] BR EVEO S.A. premium domestic bare metal cloud 53158 [BLOCK] BR Net Turbo Telecom regional consumer broadband 8151 [BLOCK] MX UNINET S.A. de C.V. Telmex core routing layer 17072 [BLOCK] MX Total Play Telecomunicaciones FTTH fiber paths 18809 [BLOCK] PA Cable Onda principal Panamanian consumer grid 23520 [BLOCK] Caribbean Columbus Networks USA Inc. automated scan risk 27947 [BLOCK] EC Telconet S.A. major corporate industrial fiber 30689 [BLOCK] JM FLOW domestic consumer broadband routing 48721 [BLOCK] PA Flyservers S.A. Panama corp; hosted inside EU 52485 [BLOCK] HN networksdelmanana.com enterprise communications 141039 [BLOCK] PA PacketHub S.A. global deployment (2 of 2 / APAC) 206971 [BLOCK] BR BedHosting BR data center server fields 207137 [BLOCK] PA PacketHub S.A. global deployment (1 of 2) 209854 [BLOCK] PA Cyberzone S.A. protected offshore arrays 262688 [BLOCK] BR MHNET Telecom rural internet transport grids 263792 [BLOCK] EC IN.PLANET S.A. Andean carrier data lines 264750 [BLOCK] DO TELEOPERADORA DEL NORDESTE S.R.L. regional block 264850 [BLOCK] HN TODAS LAS REDES SA Central American transit 266572 [BLOCK] BR WORLDNET Telecomunicações regional routing links 266827 [BLOCK] HN/Global BOHO BEACH CLUB S.A. distributed leisure network 268136 [BLOCK] BR P J A Telecomunicacoes Ltda private business net 268372 [BLOCK] BR WISESITE Comunicacao e Tecnologia application arrays 270716 [BLOCK] BR GOVISTA Telecomunicao Importacao transport logistics 271935 [BLOCK] DO AIRTIME TECHNOLOGY SRL West Indies localized systems 3132 [BLOCK] PE Red Cientifica Peruana academic/research core 21826 [BLOCK] VE Corporación Telemic C.A. commercial broadband 44382 [BLOCK] LACNIC Fiba Cloud Operation Company virtual host clusters 52393 [BLOCK] PA Corporacion Dana S.A. business app staging 263735 [BLOCK] LACNIC SOCIEDAD BUENA HOSTING, S.A. shared frameworks 263740 [BLOCK] LACNIC Corporacion Laceibanetsociety operations facility 263821 [BLOCK] LACNIC Soluciones Favorables system provisioning targets
--------------------------------------------------------------------------- 15. AFRICAN TELECOMMUNICATIONS & HOSTING --------------------------------------------------------------------------- ASN STATUS GEOGRAPHY PROVIDER / CONTEXT 37153 [BLOCK] ZA xneelo (Pty) Ltd major domestic web host core 37611 [BLOCK] ZA Afrihost SP (Pty) Ltd consumer broadband systems 43444 [BLOCK] ZA/Global Fast Servers (Pty) Ltd agile deployment clouds 204300 [BLOCK] ZA D2CLOUD NETWORK SERVICES automated framework 329184 [BLOCK] ZA Host Africa (Pty) Ltd data center group track
--------------------------------------------------------------------------- 16. ASIA-PACIFIC HOSTING & TELECOM --------------------------------------------------------------------------- ASN STATUS GEOGRAPHY PROVIDER / CONTEXT 3462 [BLOCK] TW HiNet / Data Communication core national transit 5065 [BLOCK] KR Bunny Communications app development clusters 9329 [BLOCK] LK Sri Lanka Telecom Internet national state backbone 9465 [BLOCK] SG AGOTOZ PTE. LTD. Southeast Asian hosting cells 17451 [BLOCK] ID Biznet Networks premium corporate broadband cloud 38136 [BLOCK] HK Akari Networks resilient developer servers 38623 [BLOCK] KH Viettel Cambodia Metfone national carrier line 45187 [BLOCK] AU/APAC Rackspace IT Hosting managed enterprise computing 45237 [BLOCK] MN Magicnet LLC domestic commercial host provider 45370 [BLOCK] KR BROADBANDIDC Seoul metropolitan data infrastructure 45753 [BLOCK] HK Netsec Limited proxy network edge paths 45899 [BLOCK] VN VNPT Corp national post & telecommunications core 47810 [BLOCK] GE Proservice LLC strategic institutional data center 56030 [BLOCK] NZ Voyager Internet Ltd. Kiwi business virtualization 56038 [BLOCK] AU/Global RackCorp hardened high-resilience cloud arrays 132056 [BLOCK] HK SCICUBE regional small business web host tiers 133159 [BLOCK] AU Mammoth Media Pty Ltd cloud systems engineering 133380 [BLOCK] HK Layerstack Limited high speed developer arrays 133499 [BLOCK] IN HostRoyale Technologies Pvt Ltd node array (1 of 5) 134240 [BLOCK] TH Super Broadband Network Company AIS delivery grid 134450 [BLOCK] IN HostRoyale Technologies Pvt Ltd node array (2 of 2) 135357 [BLOCK] HK Hong Kong Kowloon Telecom metropolitan fiber ring 137409 [BLOCK] AU/Global GSL Networks Pty LTD content scaling pipelines 149440 [BLOCK] MY Evoxt Sdn. Bhd. low cost global VM deployment sets 152194 [BLOCK] HK CTG Server Limited cross boundary data nodes 153656 [BLOCK] HK OWGELS INTERNATIONAL CO. wholesale global routing 153671 [BLOCK] HK Liasail Global Hongkong Limited automated virtual 203020 [BLOCK] IN HostRoyale Technologies Pvt Ltd node array (3 of 5) 203999 [BLOCK] IN/US Geekyworks IT Solutions Pvt Ltd application sandboxes 204287 [BLOCK] IN HostRoyale Technologies Pvt Ltd node array (4 of 5) 207990 [BLOCK] IN HostRoyale Technologies Pvt Ltd node array (5 of 5) 212512 [BLOCK] HK Detai Prosperous Technologies server housing 213438 [BLOCK] SC ColocaTel Inc. offshore privacy server spaces 215929 [BLOCK] HK Data Campus Limited virtualization testbeds 135377 [BLOCK] HK UCLOUD INFORMATION TECHNOLOGY review recommended 150436 [BLOCK] SG Byteplus Pte. Ltd. Bytedance corporate enterprise arm
--------------------------------------------------------------------------- 17. SECURITY SCANNERS, RESEARCH NETWORKS & PRIVACY INFRASTRUCTURE --------------------------------------------------------------------------- ASN STATUS GEOGRAPHY PROVIDER / CONTEXT 16417 [BLOCK] US Cisco Systems IronPort Division email scanner 42969 [BLOCK] DE Alpha Strike Labs GmbH active vulnerability probing 57860 [BLOCK] DK Zencurity ApS academic threat mapping research 60729 [BLOCK] Global TORSERVERS-NET Tor anonymity network exit nodes 200107 [BLOCK] CH Kaspersky Lab Switzerland GmbH malware analyzer 209366 [BLOCK] CY SEMrush CY Ltd commercial SEO search crawler 211680 [BLOCK] PT NSEC Sistemas Informaticos BitSight risk tracker 213412 [BLOCK] FR ONYPHE SAS active reconnaissance defense engine 396319 [BLOCK] LT Oxylabs global automated scraping proxy pool 398722 [REVIEW] US Censys Inc. continuous internet infrastructure scans
--------------------------------------------------------------------------- 18. CRITICAL FLAG: HIGH RISK POTENTIAL COLLATERAL DAMAGE TARGETS --------------------------------------------------------------------------- ASN STATUS GEOGRAPHY PROVIDER / CONTEXT 15699 [BLOCK] ES Adam EcoTech S.A. traditional technology firm 15830 [BLOCK] NL Equinix (EMEA) / Telecity infrastructure manager 28682 [BLOCK] SI Posta Slovenije d.o.o. national postal services 47101 [REVIEW] US City of Yakima municipal local government link 47661 [REVIEW] DE Deloitte GmbH financial consulting corporate core 47861 [REVIEW] BE Peter E. J. Durieux independent routing entry 48037 [REVIEW] NL SSC-ICT Haaglanden core Dutch government IT hub 48059 [REVIEW] BA Konzum d.o.o. Sarajevo regional retail logistics 48075 [REVIEW] BE S.W.I.F.T. SC global secure interbank banking wire 48135 [BLOCK] IT Leonardo S.p.A. major national aerospace supplier 48447 [REVIEW] UK Sectigo Limited critical global SSL auth vendor 48451 [REVIEW] CZ Prazska energetika, a.s. metropolitan power grid 48452 [REVIEW] BG Telco power Ltd regional electricity utility link 48455 [BLOCK] UK Man Investments Limited corporate asset manager 48468 [REVIEW] CH Triumph Intertrade AG commercial trade systems 48469 [REVIEW] NO mnemonic AS strategic enterprise cybersecurity 48512 [REVIEW] DE/FR EPEX SPOT S.E. wholesale power energy exchange 48514 [REVIEW] SE Stiftelsen Chalmers Studenthem university housing 48517 [BLOCK] BE Destiny N.V. domestic business broadband ISP 48518 [BLOCK] FR ADD-ON MULTIMEDIA SAS commercial media publisher 45562 [REVIEW] HK Hutchison International Ltd trade core arrays 46602 [REVIEW] US PLAIN DEALER PUBLISHING CO. traditional newsprint 395064 [REVIEW] CA Douglas College public higher education campus
--------------------------------------------------------------------------- 19. FRAMEWORK EXTENSIONS & UNCLASSIFIED NETWORKS --------------------------------------------------------------------------- ASN STATUS GEOGRAPHY PROVIDER / CONTEXT 402226 [BLOCK] US OnlyScans LLC automated asset spider indexing 64160 [BLOCK] Belize NimblyNet Limited global virtualized footprint 202053 [BLOCK] FI UPCLOUD UpCloud Ltd enterprise cloud cluster 402253 [BLOCK] KN SKN Subnet & Telecom Ltd Caribbean deployment 216071 [BLOCK] UAE/NL VDSINA - SERVERS TECH FZCO hosted in Netherlands 215607 [BLOCK] DE DF-Transit - dataforest GmbH network backbone 206216 [BLOCK] US ADVIN-AS - Advin Services LLC virtualization 52449 [BLOCK] Belize My Tech BZ localized commercial system blocks 9597 [BLOCK] JP Unknown - KDDI Web Communications host layer 400529 [BLOCK] US Infraly, LLC automated infrastructure engine 399244 [BLOCK] US AME Hosting LLC isolated server setups 401322 [BLOCK] US NetO Corp enterprise communication platform 400810 [BLOCK] US BreezeHost custom virtualization architectures 394814 [BLOCK] US ISP4Life INC high volume unmanaged transit 263744 [BLOCK] HN Udasha S.A. infrastructure platform node 42366 [BLOCK] DE TERRATRANSIT-AS - TerraTransit AG backbone 132817 [BLOCK] BD DZCRD-AS-AP - DZCRD Networks Ltd 150493 [BLOCK] ID Indonesia Network Info PT Gunung Sedayu Sentosa 24560 [BLOCK] IN Bharti Airtel Ltd. Telemedia Services core 56511 [BLOCK] PL GAMP-AS - GAMP Sp. z o.o. platform space 42220 [BLOCK] ES SIAPI-AS - TREVENQUE SISTEMAS DE INFORMACION 30900 [BLOCK] IE WEBWORLD-AS - Sternforth Ltd WebWorld 4811 [BLOCK] CN CHINANET-SHANGHAI-MAN - China Telecom 135951 [BLOCK] VN WEBICO-AS-VN - Webico Company Limited 51247 [BLOCK] LT/NL serveriotechnologijos-AS Serverio MB 203098 [BLOCK] LT tech-internet-broadband trafficforce UAB 61098 [BLOCK] CH exoscale - Akenes SA high performance framework 21013 [BLOCK] AT ITANDTEL-AS - eww ag infrastructure service 263753 [BLOCK] CL SERVICIOS DE DATACENTER DATANETWORKS LIMITADA 141968 [BLOCK] ID Indonesia Network Info PT Industri Kreatif 22363 [BLOCK] US Powerhouse Management Inc. global footprint 203003 [BLOCK] FI magna-capax - Magna Capax Finland Oy
=========================================================================== END OF DATA PROFILE ===========================================================================