
Since I migrated the blog back to my own servers a few days ago, I have realized something: I have fallen back to my old habit of watching the hit count.
This is weird, considering the lack of interest I had in my blog and its stats over the last year or so. But having my baby back home where I am in charge gives a sense that I should pay attention. That I need to know what’s happening.
In 2005, when I started doing this, I used to watch my hit count religiously, maniacally. Sort of goes with the bipolar, but I digress. In 2008, we are obsessed with followers, and the Slashdot like addiction to being the first to report some breaking (planted?) news item.
So, after three years of blogging, I see that the online communities haven’t progressed much beyond hit counters, page views, or followers. And online cred is a insular and self-perpetuating thing. You draw attention to yourself, you get comments, more people follow you, and more people feed you, you have more to say, more people follow you…and on, and on.
I am not saying that this is good, or ill. I am as much a traffic whore as the rest of the world. I just realize that we are all after the same goal – attention. That was the whole idea behind the Attention Economy, a term I don’t hear as much as I did 2 years ago.
With FriendFeed and Twitter, we live in the Attention Economy. With 200 channels in my basic cable package, TV is a passive Attention Economy, controlled by the PVR and the TorrentSphere. Satellite Radio forces us to make choices.
Be it hit-counts or PVRs, we all crave attention, knowing full well how limited the attention-span is. We don’t want be to waste our time, but we want to attract that of others.
Attention produces an unbalanced online economy. We can do many things to control the incoming flow. We can also work very hard to expand the outgoing flow. But for most of us, the outgoing flow remains a trickle, maybe even a fine mist.
So where does the power in the Attention Economy lie? With the off-switch.
And we all have one.
How do you use yours?
Author: spierzchala
Welcome to Newest Industry…
Or should I say, welcome back.
Three years ago when I started blogging on a regular basis, the blog was name The Newest Industry after the Husker Du song of the same name. Then I migrated the content to WordPress.com, and relinquished hosting it myself.
Well, I have decided to resurrect Newest Industry, but with all the same shiny content you would find at the Crazy Canuck Chronicles.
So, if it’s been a while, welcome back. Otherwise, a simple hello.
WordPress Install – Installer FAIL!
So, the last post I put up simply stated that I had failed in installing Worpress 2.6 on my own server. The permalinks were messed up and it looked a lot like an issue that a lot of people were having.
But, the catch was: the problem persisted when I tried to use WordPress 2.5.1. Hmmm…wonder what’s up.
So today, I started thinking that it might be an Apache issue, rather than a WordPress issue. So, taking a break from a massive project I’m doing (only so much performance data you can process before brain freeze), I started to poke around.
AllowOverride All
That did it. I was not letting Apache read the damn .htaccess file that WordPress installed.
Excuse the thudding of my head on the desk.
Many apologies to the Automattic team. This user haz th dumb.
WordPress Install: Fail
I decided over the weekend to have a go at running my own install of WordPress 2.6, with an aim to perhaps hosting my own blog again, with the obvious gains in flexibility and monetization.
Let’s just say that it was frustrating.
The most frustrating part was the permalink issue. All known and posted fixes failed to resolve the issue of getting the permalinks to match those seen in this blog, which is the content I would be migrating. There is no clear and simple fix for those of us who just want the software to work, without having to spend two hours hacking.
I will try again when 2.6.1 is released, but it strikes me as odd that this made it out the door. However, I have seen worse unintended features appear in released software.
identi.ca and Penalty of Success
The latest “rage” flooding through the social-media world is identi.ca, a Twitter-like micro-blogging service that is built on open-source servers and code.
As with anything that becomes an overnight sensation, the problems of success tend to follow. Using GrabPERF, I have been monitoring the HTML download time of my personal message stream. The results have been interesting.
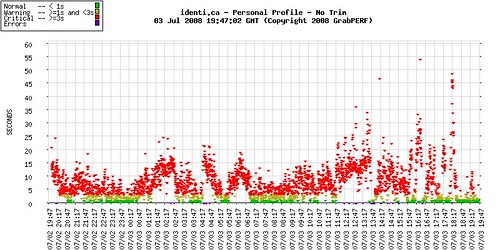
Much has been made of social-media leaders that says that this is a clone, and that it is slow, etc. But, as has also been noted, it is:
- A one-person operation
- open-source code
- willing to admit that it needs to grow.
So, one-day never makes a performance trend. Over the last week, in my day job, I have watched a large online retailer suffer a similar fate to this newcomer to the social-media arena.
And if everyone who was willing to wait for Twitter to recover waited ten seconds for identi.ca to catch up, then there is a good chance that it may stand a chance of becoming a true competitor, pushing performance improvement.
Plurk was a non-starter for the twitterati. Jaiku has lost momentum, and is failing Google in the same way that Orkut did. And Pownce…what is that?
I hold out high hopes for identi.ca, if only to keep Twitter truly honest.
Outages and the Power of Social Media
Lately, there have been outages for two large sites: Amazon and Facebook. Working for a company that monitors such things made me able to confirm the nature of the outages. But how I became aware of them has had me thinking in new ways for the last few weeks.
I became aware of both of these outages through a combination of FriendFeed and Twitter within minutes of them starting. This information spread quickly. And, due to the nature of these new technologies, people were able to comment on the outages, and theorize about the cause of the problems these large online firms faced.
The question you are likely asking is “So what?”. Well, as anyone who has been paying attention for the last four years should know, while you cannot completely control the conversation, you can participate in it and help prevent the spread of negative or incorrect theories about what is happening on your site.
The technologies that people who come to your site use to comment when something goes wrong can be used to interact with the customers. The classic example of this is Zappos. If you look on Twitter, you will find a number of members of that organization who are using the service to interact with customers on a human level. And if you have a problem or question, you stand an excellent chance of getting a response from the CEO if you ask a question.
So, if your site experiences an issue or problem, how do you interact with customers? Or do you just hope they don’t notice?
Back in Alberta. Back with my Tribe.
My grandmother died a few months back, and while this was indeed a very sad day for all of us, she left on her own terms, and with her mind intact, facing the next adventure with grace and dignity.
What this sad event did is provide a focus for the entire Pierzchala clan to reconvene for the first time in more than a decade. Tomorrow, we will going to the ancestral heartland in the Crowsnest Pass to spread her ashes, and celebrate her life.
I am staying at my Aunt Heather’s home, someone I haven’t seen or spoken to in years. And tomorrow, I will see my aunts, uncles, cousins, second cousins, etc. and feel a part of the family that I had left behind.
I am sad that I couldn’t bring the rest of my family with me, to feel a part of this larger family, and understand just how many people they are related to, this is very important to me.
These are my people. My clan. My tribe.
And it is good to be among them again.
The Twitter Debate – YATPBP
Yes, it’s YATPBP (Yet Another Twitter Performance Blog Post).
About 10 days ago, I turned GrabPERF loose on Twitter. Now before you accuse this of crippling the service and bringing it to its knees, realize that GrabPERF simply requests a document over HTTP about two times a minute. No additional requests are made for images and the like.
In the ocean of requests coming into the Twitter systems, the GrabPERF requests are like individual water molecules being added to the pool.
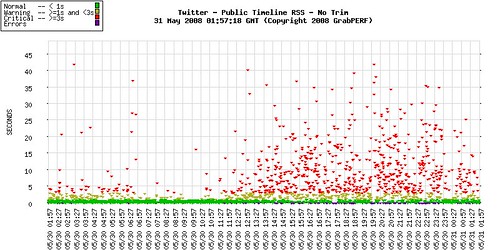
The above graph shows performance for the last 24 hours. The purple dots are errors. Complete details, and a dynamically updating graph, can be found here.
Now that I have had a chance to show off, I will leave the Twitter team in peace. I am not a developer or a systems expert. I, like most people, rely on people with specialized skills to analyze and resolve the problem. There are many people on the Web who have taken on the challenge of reverse-engineering Twitter to try and determine how it does what it does, and how they would build a better mousetrap.
Ok. Go do it. Or shut up and let the Twitter team get down to the hard work of making this service work. Or volunteer to help them fix the problems.
The Twitter team has stated that they know how to resolve the issues that are at the heart of the performance issue. But as I said in a comment to @gapingvoid tonight, knowing what the solution is only makes up 15% of the application development process. Building, testing, deploying and verifying the solution takes 85% of the effort.
The Twitter team has a lot of work ahead of them. Buy them beer and pizza and let them get to it.
It's the network, dummy
In the GigaOm blog today, Allen Leinwand puts up a monstrous wake-up call to all the hip and cool Web 2.0 companies out there: Your apps run across the Internet [here].
I have spent 9 years investigating, diagnosing, and validating the Web performance issues of companies. I can tear the Web performance data of a site down quickly and ask pointed questions about why certain components of an application are behaving poorly.
But even after 9 years, there are still gimme problems around connection setup that I can seem brilliant about, not because I have some secret knowledge, but because I think of Web performance from the Network UP, not from the Application DOWN.
The subtlety of this difference what Leinwand is alluding to. Fancy applications run across the Internet. The Internet is built on TCP. And TCP is built on-top of a very complex networking infrastructure that is way beyond the realm of my skills.
If you don’t know what packet loss looks like, or how your fancy app presents to clients, or how to ensure that this data is collected and presented to you in a timely way, then you are being exposed to alerting by client calls.
All because you thought the biggest problem was scaling your app, not ensuring that the network it crossed to reach people affected the way it performed. Network geeks created Web 1.0; Web 2.0 seems to think they are mostly unecessary.
Wrong.
Measure your performance. Understand TCP. Hire a network geek (or 20).
Then sleep better at night.
Xobni Public
If you’ve come here looking for Xobni invites, don’t bother. It’s open to all now.
Go make your Outlook less excruciating.