Google’s Core Web Vitals initiative has become a larger part of discussions that we have with customers as they begin setting new performance KPIs for 2021-2022. These conversations center on the values generated by Lighthouse, WebPageTest, and Performance Insights testing, as well as the cumulative data collected by CrUX and Akamai mPulse and how to use the collected information to “improve” these numbers.
Google has delayed the implementation of Core Web Vitals into the Page Rank system twice. The initial rollout was scheduled for 2020, but that was delayed as the initial disruption caused by the pandemic saw many sites halt all innovation and improvement efforts until the challenges of a remote work environment could be overcome. The next target date was set for May 2021, but that has been pushed back to June 2021, with a phase-in period that will last until August 2021
Why the emphasis on improving the Core Web Vitals values? The simple reason is that these values will now be used as a factor in the Google Page Rank algorithm. Any input that modifies an organization’s SEO efforts immediately draws a great deal of attention as these rankings can have a measurable effect on revenue and engagement, depending on the customer.
While conversations may start with the simple request from customers for guidance around what they can do to improve their Core Web Vitals metrics, what may be missed in these conversations is a discussion of the wider context of what the Core Web Vitals metrics represent.
The best place is to define what the Core Web Vitals are (done by Google) and how the data is collected. The criteria for gathering Core Web Vitals in mPulse is:
Visitors who engage with the site and generate Page View or SPA Hard pages and are using recent versions of Chromium-based browsers.
However, there is a separate definition, the one that affects the Page Rank algorithm. For Page Rank data, the collection criteria gets a substantial refinement:
Visitors who engage with the site and generate Page View or SPA Hard pages who (it is assumed) originated from search engine results (preferably generated by Google) and are using the Chrome and Chrome Mobile browsers.
There are a number of caveats in both those statements! When described this way, customers may start to ask how relevant these metrics are for driving real-world performance initiatives and whether improving Core Web Vitals metrics will actually drive improvement in business KPIs like conversion, engagement, and revenue.
During conversations with customer, it is also critical to highlight the notable omissions in the collection of Core Web Vitals metrics. Some of these may cause customers to be even more cautious about applying this data.
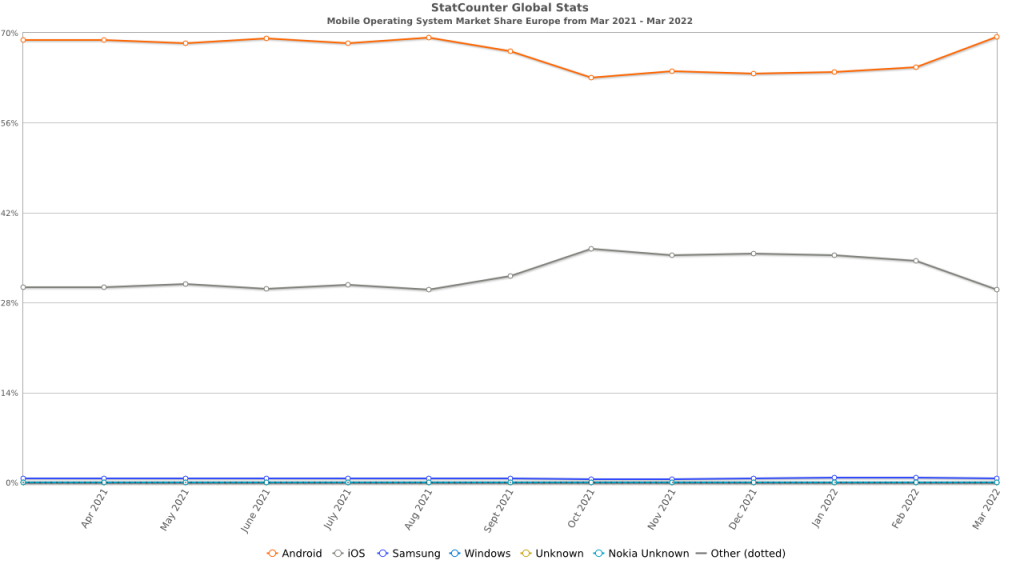
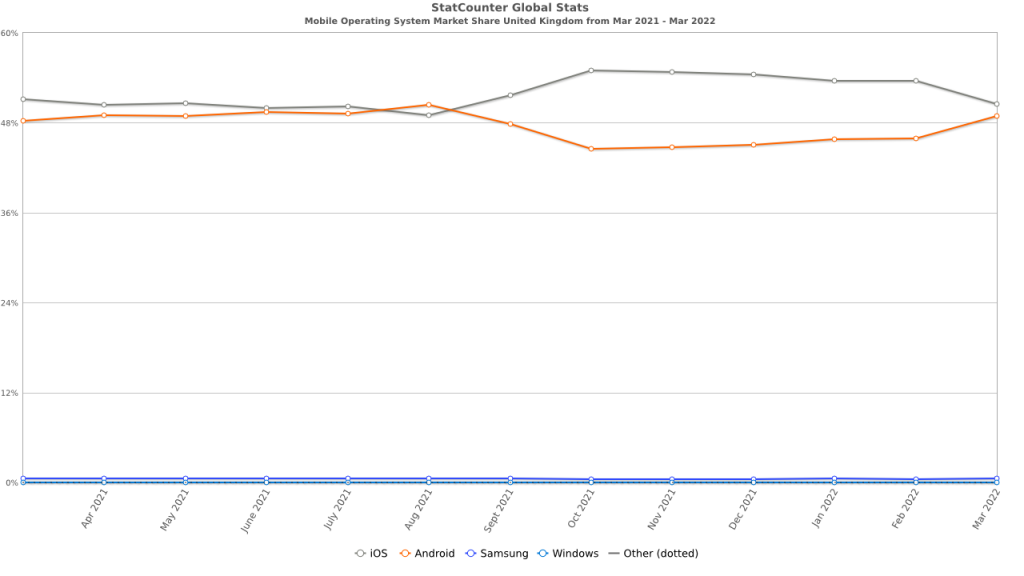
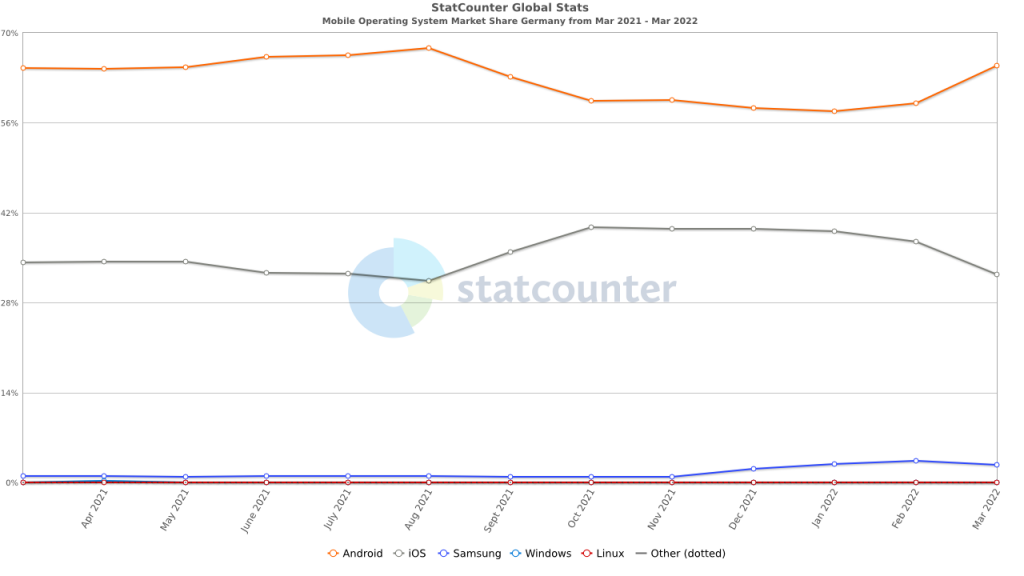
- No Data from WebKit Browsers. None of the browsers based on Webkit (Safari, Mobile Safari, Mobile Safari WebView) collect Cumulative Layout Shift or Largest Contentful Paint values. Recent updates have allowed for the collection of First Contentful Paint, but that is not one of the metrics used in Core Web Vitals. The argument can be made that Safari and Mobile Safari already deliver highly optimized web experiences, but not providing insight into a significant (if not dominant) user population will leave organizations wondering what global performance metrics (i.e., metrics collected by all browser families) they can use to represent and track the experience for all visitors.
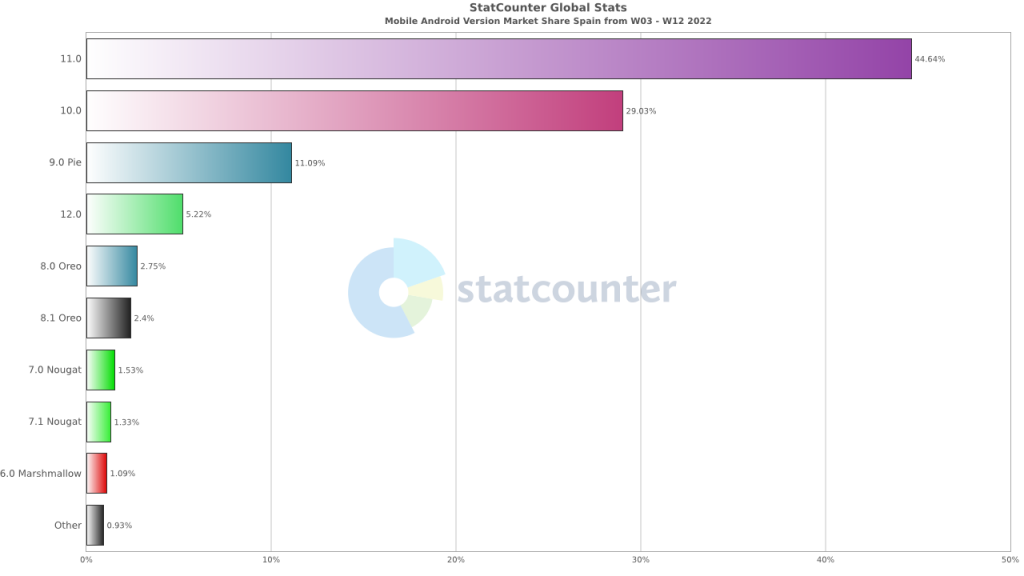
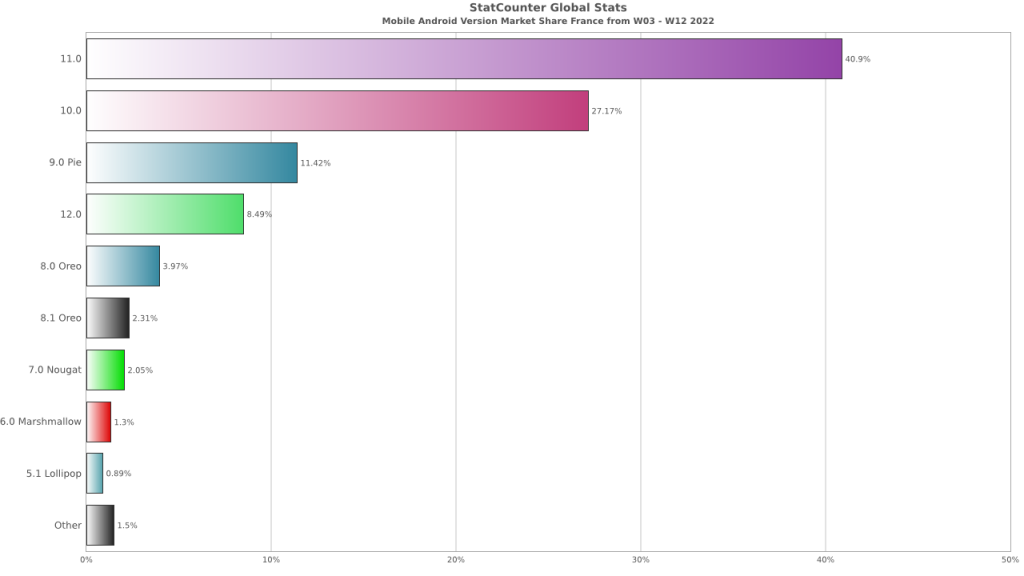
- Limitations in CrUX Data Collection. The data that Google collects for CrUX reporting only originates from Chrome and Chrome Mobile browsers. So, even though Chromium-based browsers, such as Edge and Opera, currently collect Core Web Vitals data, it is not used by Google in Page Rank. This narrow focus may further erode the focus on Core Web Vitals in organizations where Chrome and Chrome Mobile are only one part of a complex browser environment.
- Performance Delta between Mobile Safari and Chrome Mobile. With only very limited exceptions, Mobile Safari substantially outperforms Chrome Mobile in standard performance measurement metrics (Time to Visually Ready, Page Load, etc.). This forces organizations to focus on optimizing Chrome Mobile performance, which is substantially more challenging due to the diversity in the Android device and OS population. As well, without a proven business reason, getting customers to update their mobile performance experience based on Core Web Vitals data could become challenging once this exception is realized.
- Exclusion of SPA Soft Navigations. Up until recently, none of the Core Web Vitals metrics were captured for SPA Soft Navigations (see below for changes to Cumulative Layout Shift). This is understandable as the focus for Google is the performance of pages originating from Google Search Results, and navigating from the results will not generate a SPA Soft navigation. However, the performance and experience advantages of SPA Soft Navigations for visitors is almost completely lost to Core Web Vitals.
- Current Lack of Clear Links Between Core Web Vitals and Business KPIs. Google has been emphasizing the Core Web Vitals as the new the new metrics that companies should use to guide performance decisions. However, there has yet to be much (or any) evidence that can be used to show organizations that improving these metrics leads to increased revenue, conversions, or engagement. Without quantifiable results that link these new performance KPIs to improvements in business KPIs, there may be hesitancy to drive efforts to improve these metrics.
Google is, however, listening to feedback on the collection of Core Web Vitals. Already there have been changes to the Cumulative Layout Shift (CLS) collection methodology that allow it to more accurately reflect long-running pages and SPA sites. This does lead to some optimism that the collection of Core Web Vitals data may evolve over time so that it includes a far broader subset of browsers and customer experiences, reflecting the true reality and complexity of customer interactions on the modern web application.
Exposing the Core Web Vitals metrics to a wider performance audience will lead to customer questions about web performance professionals are using this information to shape performance strategies. Overall, the recommendation thus far is to approach this data with caution and emphasize the current focus these metrics have (affecting Page Rank results), the limitations that exist in the data collection (limited browser support, lack of SPA Soft Navigations, mobile data only from Android), and the lack of substantial verification that improving Core Web Vitals has a quantifiable positive effect on business KPIs.