
The new GrabPERF Agent code, with support for plain text or regular expression content matching, is now in production on all active measurement agents.
I added one more feature before I rolled out the new code: when a content match error occurs, the server headers and HTML content for 14 days.
I have not exposed this feature yet, but will be doing so in the next few days.
Again, thanks to the GrabPERF community for your continued support.
Technorati Tags: GrabPERF, Web+performance, Text+match, Content+match, Agent+upgrade
Category: Uncategorized
GrabPERF: CrunchGear Crunched
Michael Arrington’s latest Crunch product, CrunchGear, is getting beat up this morning.
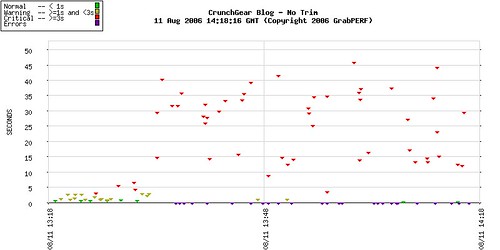
Ouch!
In the past, these would not appear as errors, but the new text match feature in GrabPERF is working like a charm. The new code is up on 3 of the 5 measurement agents, and the remaining 2 should be updated by tomorrow.
Technorati Tags: GrabPERF, Web+performance, CrunchGear, TechCrunch, Michael+Arrington
Blog Search: Technorati, where art thou bot?
July 25, 2006 at 19:48:24 GMT.
That’s the last time that the Technorati bot indexed my blog.
I am confused, because of all the sites out there, my blog should be pretty easy for Technorati to index — this server, as well as the GrabPERF servers is hosted in Technorati’s racks. Theoretically, the bot should be able to index my blog without leaving the building.
I posted something this morning, and IceRocket, Google Blogsearch, Ask.com Blog Search all have it.
I am wondering if anyone else is noticing this.
Technorati Tags: Technorati, Tags, Indexing, bots, search, blog+search
Work: Start-up v. Established Firm — Thoughts on Inflection Points
Scott Berkun wrote a great post that discusses how he encounters the start-up inflection point in companies. This is the point where the company has to make that brutal transition from the fast-and-loose dynamic of the true start-up to the more established and “normal” business methods.
This week, Niall Kennedy provided an example of someone who gave an established firm a try, but decided that the start-up world is more to his liking.
The object here is not to decide which is best, the start-up or the established firm, but to discuss the transition that occurs when moving between these two phases; and the direction of travel is always one-way, to the established firm. For all their talk of “thinking like a start-up”, established firms are what they are.
I have made this transition twice now. The first time was during the exuberance of the 1999 bubble world with a company that had just gone public. Here the transition was initially hidden by the exponential growth and overly optimistic predictions made by the executives. When reality stepped in early in 2001, the true effect of the transition became clear: this was no longer a start-up, and there were people who were more than willing to make the tough decisions. Whether, in the long-term, these were the correct decisions is a question that I am not willing to answer; I was merely an observer.
I was an observer when a similar change occurred at my current company. A start-up in the sense that it was still a VC-funded private firm, this company had (and still has) an excellent product developed by some top-flight technical talent. The issue now was to take that foundation and build a team that could execute. Again, I can’t say whether the decisions that were made were the correct ones, but the team that was built during that time has lead the company out of the wilderness and in a very solid direction.
These are simply my experiences. In my experience, there are start-up people and established company people; and there are the rare folks who can slide in and out of both worlds. Me, I fall into the start-up category. When a company starts edging toward 200 employees, I begin to feel a bit edgy. In a very quick exchange I had with Niall Kennedy on Tuesday, he said that he set a magic number whan a company became a “189” “187” (a number he also mentioned was police slang for homicide).
Is there a magic number? Or does it depend on the company? What defines a start-up? What defines an established firm?
Technorati Tags: start-up, established+firm, big+company, Niall+Kennedy, Scott+Berkun, Inflection+Point, transition, management
GrabPERF: Text Matching Example
I now have a true live example of how text matching can provide information on issues where a successful page is returned.
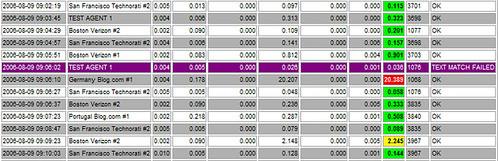
In this example, the TEST AGENT returned a Text Match Failed error, while 3 of the agents running the current production code said the page was a success.
How do I know that the TEST AGENT is right? Take a look at the byte count. For the successful pages, the byte count is in the 3,600-3,900 byte range; the page that had the Text Match failure only returned 1076 bytes. And three other measurements around that time reported the same approximate size, but reported successful page downloads.
If this Agent code shows continued success and robust behaviour, then I will push it into production on August 14.
Technorati Tags: GrabPERF, Agent+upgrade, Web+performance, text+match, content+match
GrabPERF: New Feature – Text Matching
Ok folks, this is it. I have finally truly woken up from my slumber and I am starting to add features to the system.
Today’s latest: content | text matching.
This is a critical step in the development, as it allows for quality checking against the returned data. Currently, I can only catch errors under 3 defined circumstances:
- The server returns an HTTP code >= 400
- The measurement times out when delivering the data (45 seconds)
- The connection to the server fails (only some agents and kernels)
Now, the ability to confirm that the data being returned under what would be considered by the server admins as a success criteria, i.e. something with an HTTP/200 OK message got sent back to the client, can trigger an error in a defined text string or regular expression does not appear in the HTML.
This is currently up on a test agent, and if it proves stable, I will roll it out to the production agents later this week. If you would like to be a part of this beta, drop me a line or a comment.
Technorati Tags: GrabPERF, Web+performance, Text+matching, Content+matching, quality+check
Performancing Extension: Trying something new
Since I started using the Performancing Firefox extension, it seems that Technorati takes a while to find me. FInally figured out that I haven’t enabled pings.
So this is a test post to see if the ping function works correctly.
Technorati Tags: Performancing, Firefox, Technorati
Notebook Lust: Archimedes Palimpsest
For history fiends, enthusiasts of lost treasures, and lovers of a good mystery, the discovery of the Archimedes Palimpsest has been one of those stories that must be followed.
The texts contained in the Palimpsest were lost to humanity for hundreds of years as a result of a common Medieval European tradition — the re-use of parchment. To quote the site:
“The word Palimpsest comes from the Greek Palimpsestos, meaning “scraped again”. Medieval manuscripts were made of parchment, especially prepared and scraped animal skin. Unlike paper, parchment is sufficiently durable that you can take a knife to it, and scrape off the text, and over write it with a new text. In this case, [the text of Archimedes’] five books were taken apart, the text was scraped off the leaves, which were then stacked in a pile, ready for reuse.”
Using a new x-ray scanning technology, the original Greek text is exposed to the Western world for the first time since 1229.

This holds more than a passing interest to me, as one of the most influential history courses I took during my undergrad tenure was taught by a paleographer and historian at the University of Victoria, Michèle Mulchahey (she is now part of the faculty at the University of Toronto). I still often wish I had continued my Medieval European history studies, but my lack of latin prevented me from go much further than I did.
Glad to see a truly old classic resurrected.
GrabPERF: TailRank back on, and behaving well
Got an e-mail from Kevin Burton of TailRank this weekend saying that he had found some issue with the system’s infrastructure and that he should be back to normal performance.
Looking at this graph, I agree with him.
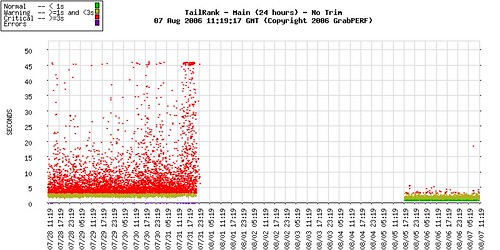
Technorati Tags: GrabPERF, Web performance, TailRank
GrabPERF: Some bad data leaked in
I was trying yesterday to debug an issue that was appeared to be affecting the PubSub Agent — yes, I re-started it at the request of their sysadmin.
The issue was that it was showing data that appeared to have no relationship with the data appearing from all of the other measurement locations. I tried blocking it off using IPTables, MySQL restrictions, etc.
This afternoon, I figured out the problem.
Yesterday, I had been using this query to diagnose the problem:
select
*
from
data
where
agent_id = 11
and date between subdate(now(),interval 30 minute) and now()
order by
date DESC
And everytime I looked, there was new data. I couldn’t seem to stop the agent from delivering data. Then I had a flash.
select
count(*)
from
data
where
agent_id = 11
and date > now()
157,000 rows of data. From the future.
Thankfully I know the guy who is responsible for keeping the PubSub servers running, and he is going to adjust the time, etc. But he makes no promises about how long the agent machine will stay running.
I apologize for the bad data.
Technorati Tags: GrabPERF, PubSub, Web Performance, The Future